Hardware Reference
In-Depth Information
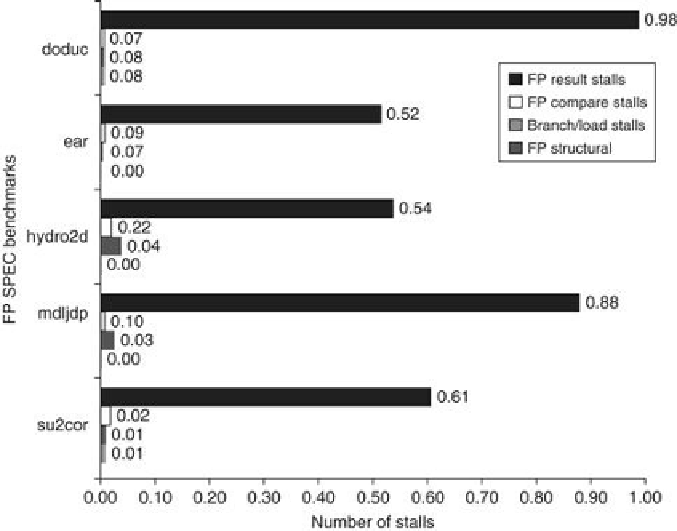
FIGURE C.40
The stalls occurring for the MIPS FP pipeline for five of the SPEC89 FP
benchmarks
. The total number of stalls per instruction ranges from 0.65 for su2cor to 1.21 for
doduc, with an average of 0.87. FP result stalls dominate in all cases, with an average of 0.71
stalls per instruction, or 82% of the stalled cycles. Compares generate an average of 0.1 stalls
per instruction and are the second largest source. The divide structural hazard is only signific-
ant for doduc.
C.6 Putting It All Together: The MIPS R4000 Pipeline
In this section, we look at the pipeline structure and performance of the MIPS R4000 processor
family, which includes the 4400. The R4000 implements MIPS64 but uses a deeper pipeline
than that of our five-stage design both for integer and FP programs. This deeper pipeline al-
lows it to achieve higher clock rates by decomposing the five-stage integer pipeline into eight
stages. Because cache access is particularly time critical, the extra pipeline stages come from
decomposing the memory access. This type of deeper pipelining is sometimes called
super-
pipelining
.
Figure C.41
shows the eight-stage pipeline structure using an abstracted version of the data
path.
Figure C.42
shows the overlap of successive instructions in the pipeline. Notice that, al-
though the instruction and data memory occupy multiple cycles, they are fully pipelined, so
that a new instruction can start on every clock. In fact, the pipeline uses the data before the
cache hit detection is complete;
Chapter 2
discusses how this can be done in more detail.
Search WWH ::

Custom Search