Hardware Reference
In-Depth Information
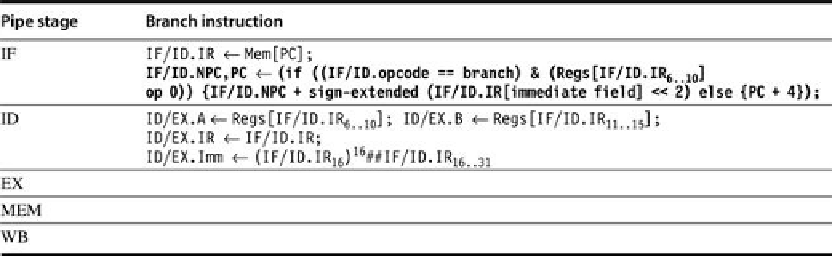
FIGURE C.29
This revised pipeline structure is based on the original in
Figure C.23
.
It
uses a separate adder, as in
Figure C.28
, to compute the branch-target address during ID.
The operations that are new or have changed are in bold. Because the branch-target address
addition happens during ID, it will happen for all instructions; the branch condition (
Regs[IF/
ID.IR
6..10
]
op
0
) will also be done for all instructions. The selection of the sequential PC or the
branch-target PC still occurs during IF, but it now uses values from the ID stage that corres-
pond to the values set by the previous instruction. This change reduces the branch penalty by
2 cycles: one from evaluating the branch target and condition earlier and one from controlling
the PC selection on the same clock rather than on the next clock. Since the value of cond is
set to 0, unless the instruction in ID is a taken branch, the processor must decode the instruc-
tion before the end of ID. Because the branch is done by the end of ID, the EX, MEM, and WB
stages are unused for branches. An additional complication arises for jumps that have a
longer offset than branches. We can resolve this by using an additional adder that sums the
PC and lower 26 bits of the IR after shifting left by 2 bits.
In some processors, branch hazards are even more expensive in clock cycles than in our ex-
ample, since the time to evaluate the branch condition and compute the destination can be
even longer. For example, a processor with separate decode and register fetch stages will prob-
ably have a
branch delay
—the length of the control hazard—that is at least 1 clock cycle longer.
The branch delay, unless it is dealt with, turns into a branch penalty. Many older CPUs that
implement more complex instruction sets have branch delays of 4 clock cycles or more, and
large, deeply pipelined processors often have branch penalties of 6 or 7. In general, the deeper
the pipeline, the worse the branch penalty in clock cycles. Of course, the relative performance
effect of a longer branch penalty depends on the overall CPI of the processor. A low-CPI pro-
cessor can afford to have more expensive branches because the percentage of the processor's
performance that will be lost from branches is less.
C.4 What Makes Pipelining Hard to Implement?
Now that we understand how to detect and resolve hazards, we can deal with some complic-
ations that we have avoided so far. The first part of this section considers the challenges of
exceptional situations where the instruction execution order is changed in unexpected ways.
In the second part of this section, we discuss some of the challenges raised by different instruc-
tion sets.
Search WWH ::

Custom Search