Information Technology Reference
In-Depth Information
Mixed Prediction and Prediction of Classifiers
Variational Bound and Number of Classifiers
-150
5
data
pred +/- 1sd
gen. fn.
cl. 1
cl. 2
L(q)
K
1.5
-160
4
1
0.5
-170
3
0
-0.5
-180
2
-1
-190
1
-1.5
-2
-200
0
0
0.5
1
1.5
2
2.5
3
3.5
4
0
1000
2000
3000
4000
5000
Input x
MCMC step
(a)
(b)
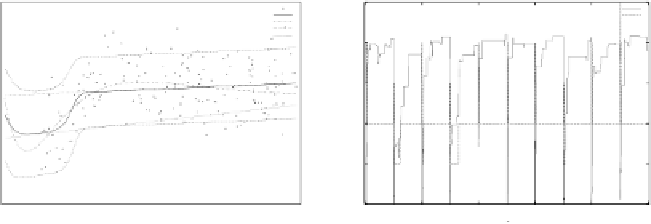
Fig. 8.9.
Plots similar to the ones in Fig. 8.6, when using MCMC model structure
search applied to the function as given in [227]. The best discovered model structure
is given by
μ
1
=0
.
56
,σ
1
=0
.
025 and
μ
2
=2
.
40
,σ
2
=0
.
501.
classifier. The model structure search, however, has identified a model that only
requires 2 classifiers by having a global classifier that models the straight line,
interleaved by a specific classifier that models the bump. This clearly shows that
the applied model selection method prefers simpler models over more complex
ones, in addition to the ability of handling rather noisy data.
8.3.4
Function with Variable Noise
One of the disadvantages of XCS, as discussed in Sect. 7.1.1, is that the desired
mean absolute error of each classifier is globally specified by the system parame-
ter
0
. Therefore, XCS cannot properly handle data where the noise level varies
significantly over the input space. The introduced LCS model assumes constant
noise variance at the classifier level, but does not make such an assumption at
the global level. Thus, it can handle cases where each classifier requires to accept
a different level of noise, as is demonstrated by the following experiment.
Similar, but not equal to the study by Waterhouse et al. [227], the target
function has two different noise levels. It is given for
−
1
≤
x
≤
1by
f
(
x
)=
−
(0
,
0
.
1) otherwise. Thus,
the V-shaped function has a noise variance of 0
.
6below
x
=0,andanoise
variance of 0
.
1 above it. Its mean and 200 data points that are used as the data
set are shown in Fig. 8.10. To assign each classifier to a clear interval of the input
space, soft interval matching is used.
Both GA and MCMC search were applied with with the same settings as
before, with the initial number of classifiers sampled from
1
−
2
x
+
N
(0
,
0
.
6) if
x<
0, and
f
(
x
)=
−
1+2
x
+
N
(8
,
0
.
5). The best
discovered model structures are shown for the GA in Fig. 8.11, with
B
L
(
q
)+
ln
K
!
≈−
63
.
12, and for MCMC search in Fig. 8.12, with a slightly better
L
(
q
)+
ln
K
!
58
.
59. The reject rate of the MCMC search was about 96
.
6%.
In both cases, the model structure search was able to identify two classifiers
with different noise variance. The difference in the modelled noise variance is
≈−























































































































































Search WWH ::

Custom Search