Databases Reference
In-Depth Information
If the outer table contains a high number of rows, then this option performs poorly. This usually indicates
that an index is needed on the inner table. If the inner table had an appropriate index, then the other two
options would usually be a better option.
Note that the cost of a nested loop join is easily determined. Simply multiply the size of the outer table
by the size of the inner table.
Merge Joins
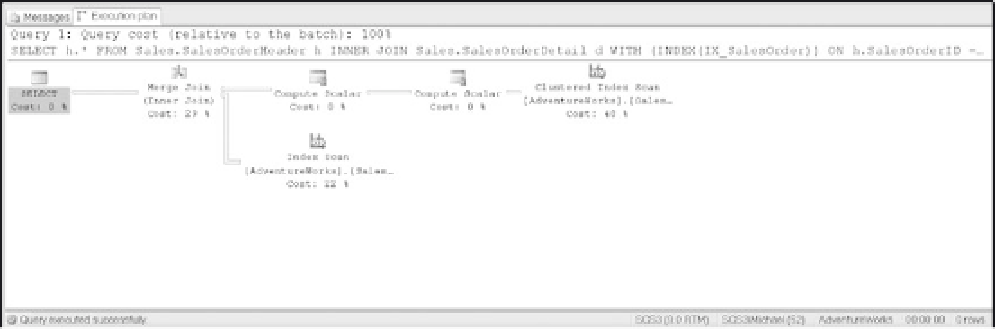
A merge join will be used when the two join inputs are both sorted on the join column. The following
querywilluseaMergeJoinandthequeryplanisshowninFigure9-6:
SELECT h.*
FROM Sales.SalesOrderHeader h
INNER JOIN Sales.SalesOrderDetail d WITH (INDEX(IX_SalesOrder))
ON h.SalesOrderID = d.SalesOrderID
Figure 9-6
Note that the optimizer is forced to use a merge join by including the following table hint:
WITH (INDEX(IX_SalesOrder)).)
Essentially, a merge join works by taking two sorted lists and merging them into one. In this example,
there are two stacks of sales information. The first stack contains header information about a sale such
as the salesman, customer, and due date. The second stack contains the details of each sale, such as the
product number and quantity. In this example, both stacks are sorted by SalesOrderID. The result is that
each customer's sales include the details of the products purchased. Because both stacks are sorted by the
same column, there only needs to be one pass through each stack.
The cost of a merge join can be calculated as the sum of the number of rows in the inputs. Thus, the fact
that the cost of a merge join is the sum of the row counts of the inputs and not a product means that
merge joins are usually a better choice for larger inputs.












Search WWH ::

Custom Search