Databases Reference
In-Depth Information
The optimizer will generally choose a merge join when both join inputs are already sorted on the
join column. Sometimes, even if a sort must be done on one of the input columns, the optimizer
might decide to do that and follow up with a merge join, rather than use one of the other available
join strategies.
Hash Joins
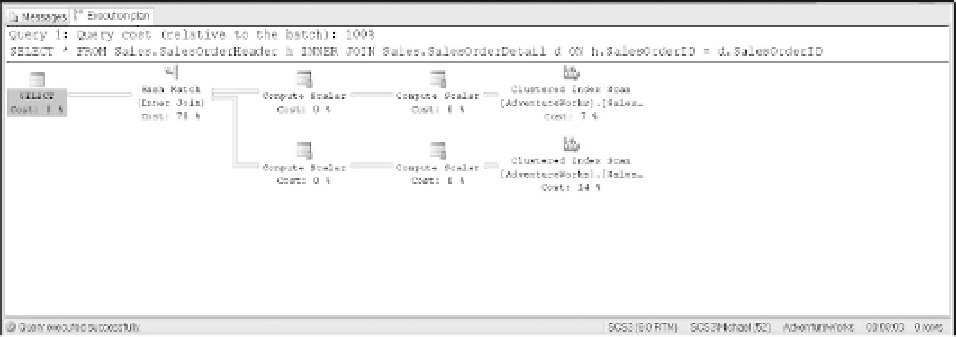
Hash joins are used when no useful index exists on the join column in either input. They're also
used when one table is much smaller than the other. Also, hash joins work well when SQL Server
must perform joins of very large tables. See Figure 9-7 for an example of a query plan with a
hash join.
SELECT *
FROM Sales.SalesOrderHeader h
INNER JOIN Sales.SalesOrderDetail d
ON h.SalesOrderID = d.SalesOrderID
Figure 9-7
SQL Server performs hash joins by completing two phases. The first phase is known as the build phase,
and the second phase is known as the probe phase.
In the build phase all rows from the first input, known as the build input, are used to build a
structure known as a hash table. This hash table will be built using a hashing function based on
the equijoin columns. The hash table will contain some number of buckets in which data can
be placed. Also, note that the hash table is created in memory if possible. In fact, SQL Server
stores these buckets as linked lists. The key to an effective hash table is using a hashing function that will
divide the data in sets of manageable size with roughly equal membership. Also note
that SQL Server will attempt to use the smaller of the two query inputs as the basis for the
build phase.
After the hash table is built, the second phase can begin. This is the probe phase. It works by
taking one row at a time and trying to find a match in the hash table. If a match is found, then it
is output.












Search WWH ::

Custom Search