Databases Reference
In-Depth Information
In order to show the three types of join operators the following changes to the AdventureWorks database
were made:
❑
The SalesOrderID column was removed from the primary key definition of Sales.SalesOrderDetail.
This left only the SalesOrderDetailID as the primary key.
❑
A new index was created on Sales.SalesOrderDetail called IX_SalesOrder. This index included
the SalesOrderID.
Nested Loop Joins
This is the default strategy for processing joins. SQL Server will evaluate this technique first. This works
by taking a row from the first table, known as the
outer table
, and uses that row to scan the second table,
known as the
inner table
. Be aware that this scan is not a table scan; it's usually done with an index.
Furthermore, if no appropriate indexes are available in the inner table, a nested loop join won't typically
be used. Instead a hash match join will be used. See Figure 9-5 for an example of a query plan with a
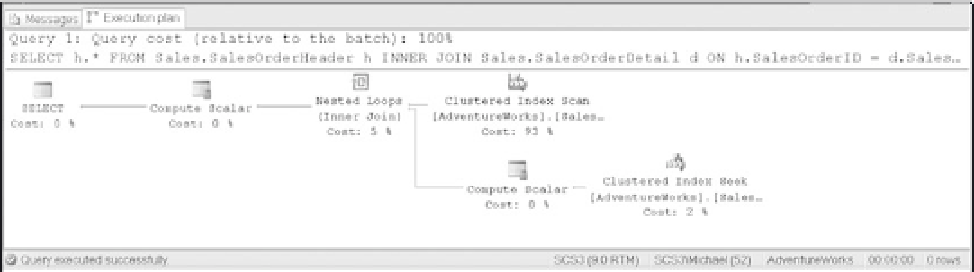
nested loop join.
Figure 9-5
Using the AdventureWorks database with the previous changes, the following query will use a Nested
Loop Join.
SELECT h.*
FROM Sales.SalesOrderHeader h
INNER JOIN Sales.SalesOrderDetail d
ON h.SalesOrderID = d.SalesOrderID
WHERE
d.CarrierTrackingNumber = '4911-403C-98'
In this case the optimizer designated the SalesOrderDetail table as the outer table. The reason is
that the where clause limits the SalesOrderDetail table to just a few rows. Thus, the optimizer deter-
mined that using a few rows to apply to the inner table, in this case SalesOrderHeader, will be the
lowest cost.
This scenario is ideal for Nested Loop joins. However, this is also the fallback option for the
optimizer. This means that if the other two join operators are unavailable then this option will be used.
Sometimes this isn't desirable.












Search WWH ::

Custom Search