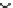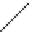Database Reference
In-Depth Information
Fig. 10.2
Prefix tree showing
prefix-based 1-length
equivalence classes in the
itemset lattice for
I
={
a
,
b
,
c
,
d
}
null
a
c
b
d
ac
ab
ad
bc
bd
cd
abc
abd
acd
bcd
abcd
Fig. 10.3
Suffix tree showing
suffix-based 1-length
equivalence classes in the
itemset lattice for
I
null
a
c
b
d
={
a
,
b
,
c
,
d
}
ac
ab
bc
ad
bd
cd
abc
abd
acd
bcd
abcd
encountered in the database, i.e. its support count. Details for the construction of the
hash tree can be found in the work of Agrawal and Srikant [
1
].
2.2.2
Pattern Growth
Apriori-based algorithms process candidates in a breath-first search manner, de-
composing the itemset lattice into level-wise itemset-size based equivalence classes:
k
-itemsets must be processed before (
k
1)-itemsets. Assuming a lexicographic or-
dering of itemset items, the search space can also be decomposed into prefix-based
and suffix-based equivalence classes. Figures
10.2
and
10.3
show equivalence classes
for 1-length itemset prefixes and 1-length itemset suffixes, respectively, for our test
database. Once frequent 1-itemsets are discovered, their equivalence classes can
be mined independently. Patterns are
grown
by appending (prepending) appropriate
items that follow (precede) the parent's last (first) item in lexicographic order.
Zaki [
63
] was the first to suggest prefix-based equivalence classes as a means of
independent sub-lattice mining in his algorithm, Equivalence CLAss Transforma-
tion (ECLAT). In order to improve candidate support counting, Zaki transforms the
transactions into a
vertical database
format. In essence, he creates an inverted index,
storing, for each itemset, a list of tids it can be found in. Frequent 1-itemsets are
then those with at least
+
σ
|
T
|
listed tids. He uses lattice theory to prove that if two