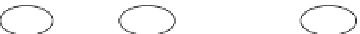Database Reference
In-Depth Information
null
a
(7)
c
(2)
d
(1)
a
b
c
(5)
b
(2)
b
(1)
d
(1)
c
b
(3)
d
(1)
d
(1)
d
(1)
d
d
(1)
Fig. 10.4
The FP-tree built from the transaction set in Table
10.1
itemsets
C
1
and
C
2
are frequent, so will their intersection set
C
1
∩
C
2
be. After creat-
ing the vertical database, each equivalence class can be processed independently, in
either breath-first or depth-first order, by recursive intersections of candidate itemset
tid-lists, while still taking advantage of the downward closure property. For exam-
ple, assuming
is infrequent, we can find all frequent itemsets having prefix
a
by
intersecting tid-lists of
{
b
}
{
a
}
and
{
c
}
to find support for
{
ac
}
, then tid-lists of
{
ac
}
and
{
d
}
to find support for
{
acd
}
, and finally tid-lists of
{
a
}
and
{
d
}
to find support for
{
ad
}
. Note that the
{
ab
}
-rooted subtree is not considered, as
{
b
}
is infrequent and
will thus not be joined with
.
A similar divide-and-conquer approach is employed by Han et al. [
21
]in
FP-growth, which decomposes the search space based on length-1 suffixes. Ad-
ditionally, they reduce database scans during the search by leveraging a compressed
representation of the transaction database, via a data structure called an FP-tree. The
FP-tree is a specialization of a prefix-tree, storing an item at each node, along with
the support count of the itemset denoted by the path from the root to that node.
Each database transaction is mapped onto a path in the tree. The FP-tree also keeps
pointers between nodes containing the same item, which helps identify all itemsets
ending in a given item. Figure
10.4
shows an FP-tree constructed for our example
database. Dashed lines show item-specific inter-node pointers in the tree.
Since the ordering of items within a transaction will affect the size of the FP-tree,
a heuristic attempt to control the tree size is to insert items into the tree in non-
increasing frequency order, ignoring infrequent items. Once the FP-tree has been
generated, no further passes over the transaction set are necessary. The frequent
itemsets can be mined directly from the FP-tree by exploring the tree from the
bottom-up, in a depth-first fashion.
A concept related to that of equivalence class decomposition of the itemset lattice
is that of
projected databases
. After identifying a region of the lattice that can be
mined independently, a subset of
{
a
}
can be retrieved that only contains itemsets
represented in that region. This subset, which may be much smaller than the original
T