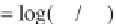Geoscience Reference
In-Depth Information
It is important to evaluate the data properties prior to the application of
a clustering algorithm. h e absolute values of the variables should i rst be
considered. For example a geochemical sample from volcanic ash might
show an SiO
2
content of around 77% and a Na
2
O contents of only 3.5%, but
the Na
2
O content may be considered to be of greater importance. In such
a case the data need to be transformed so that they have means equal to
zero (
mean centering
). Dif erences in both the variances and the means are
corrected by
standardizing
, i.e., the data are standardized to means equal
to zero and variances equal to one. Artifacts arising from closed data, such
as artii cial negative correlations, are avoided by using
Aitchison's log-ratio
transformation
(Aitchison 1984, 1986). h is ensures data independence
and avoids the constant sum normalization constraints. h e log-ratio
transformation is
where
x
tr
denotes the transformed score (
i
=1, 2, 3, …,
d
-1) of some raw
data
x
i
. h e procedure is invariant under the group of permutations of the
variables, and any variable can be used as the divisor
x
d
.
As an exercise in performing a cluster analysis, the sediment data stored in
sediment_3.txt
are loaded. h is data set contains the percentages of various
minerals contained in sediment samples. h e sediments are sourced from
three rock types: a magmatic rock containing amphibole (
amp
), pyroxene
(
pyr
) and plagioclase (
pla
), a hydrothermal vein characterized by the
presence of l uorite (
l u
), sphalerite (
sph
) and galena (
gal
), some feldspars
(plagioclase and potassium feldspars,
ksp
) and quartz, and a sandstone unit
containing feldspars, quartz and clay minerals (
cla
). Ten samples were taken
from various levels in this sedimentary sequence, each containing varying
proportions of these minerals. First, the distances between pairs of samples
can be computed. h e function
pdist
provides many dif erent measures of
distance, such as the Euclidian or Manhattan (or city block) distance. We use
the default setting which is the Euclidian distance.
clear
data = load('sediments_3.txt');
Y = pdist(data);
h e function
pdist
returns a vector
Y
containing the distances between
each pair of observations in the original data matrix. We can visualize the
distances in another pseudocolor plot.
imagesc(squareform(Y)), colormap(hot)