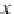Geoscience Reference
In-Depth Information
h is measure is used if one is interested in the ratios between the variables
measured on the objects. However, Pearson's correlation coei cient is
highly sensitive to outliers and should be used with care (see also Section
4.2).
• the
inner-product similarity index
- Normalizing the length of the data
vectors to a value of one and computing their inner product yields
another important similarity index that is ot en used in transfer function
applications. In this example a set of modern l ora or fauna assemblages
with known environmental preferences is compared with a fossil sample,
in order to reconstruct past environmental conditions.
h e inner-product similarity varies between 0 and 1. A zero value suggests
no similarity and a value of one represents maximum similarity.
h e second step in performing a cluster analysis is to rank the groups by
their similarity and to build a hierarchical tree, visualized as a dendrogram.
Most clustering algorithms simply link the two objects with the highest
level of similarity or dissimilarity (or distance). In the following steps, the
most similar pairs of objects or clusters are linked iteratively. h e dif erence
between clusters, each made up of groups of objects, is described in dif erent
ways depending on the type of data and the application:
•
K-means clustering
uses the Euclidean distance between the multivariate
means of a number of
K
clusters as a measure of the dif erence between
the groups of objects. h is distance is used if the data suggest that there is
a true mean value surrounded by random noise. Alternatively,
•
K-nearest-neighbors clustering
uses the Euclidean distance of the nearest
neighbors as measure of this dif erence. h is is used if there is a natural
heterogeneity in the data set that is not attributed to random noise.