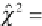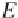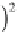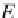Geoscience Reference
In-Depth Information
5.8539
stats =
fstat: 3.4967
df1: 59
df2: 59
h e result
h=1
suggests that we can reject the null hypothesis. h e
p
-value is
extremely low and very close to zero suggesting that the null hypothesis is
very unlikely. h e 95% coni dence interval is [2.0887,5.8539], which again in-
cludes the theoretical ratio
var(corg1)/var(corg2)
of 5.0717
2
/1.4504
2
=3.4967.
3.9 The χ
2
-Test
h e ˇ
2
-test introduced by Karl Pearson (1900) involves the comparison of
distributions, allowing two distributions to be tested for derivation from the
same population. h is test is independent of the distribution that is being
used and can therefore be used to test the hypothesis that the observations
were drawn from a specii c theoretical distribution.
Let us assume that we have a data set that consists of multiple chemical
measurements from a sedimentary unit. We could use the ˇ
2
-test to test the
null hypothesis that these measurements can be described by a Gaussian
distribution with a typical central value and a random dispersion around
it. h e
n
data are grouped in
K
classes, where
n
should be above 30. h e
frequencies within the classes
O
k
should not be lower than four and should
certainly never be zero. h e appropriate test statistic is then
where
E
k
are the frequencies expected from the theoretical distribution (Fig.
3.14). h e null hypothesis can be rejected if the measured ˇ
2
value is higher
than the critical ˇ
2
value, which depends on the number of degrees of freedom
ʦ=
K
-
Z
, where
K
is the number of classes and
Z
is the number of parameters
describing the theoretical distribution plus the number of variables (for
instance,
Z
=2+1 for the mean and the variance from a Gaussian distribution
of a data set for a single variable, and
Z
=1+1 for a Poisson distribution for a
single variable).
As an example we can test the hypothesis that our organic carbon
measurements contained in
organicmatter_one.txt
follow a Gaussian
distribution. We must i rst load the data into the workspace and compute the
frequency distribution
n_obs
for the data measurements using eight classes.