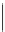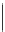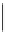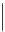Cryptography Reference
In-Depth Information
wir Wiederholungen im Geheimtext, denen Wiederholungen des Klartextes ent-
sprechen.
In Hamburg lebten zwei Ameisen, Die wollten nach Australien reisen.
TL YIWMSIO VPZKMX KU
VQ K
X
CZA
..
OY
,
...
BZM GZJC
BOY LRKR LSJBBLJZMX C
CZAOY
.
Bei Altona auf der Chaussee, Da taten ihnen die Beine weh,
Z
VQ K
WRFVK LSW
LOC
AYIEDQVM, NL RR
BOY GYV OY
...
BZM LPGEM GPF,
und da verzichteten sie weise, Dann auf den letzten Teil der Reise.
LVN OY MMBKGTPDP
RVV
CTC NMSDC
UIXY YLN NPL CMDK
RVV
DPGC
LOC
PVQCP
Sich wiederholende Passagen haben wir im Text hervorgehoben. Wir bestimmen
ihre Abstände und berechnen deren größten gemeinsamen Teiler
t
. Die tatsäch-
liche Schlüssellänge sollte ein Teiler von
t
sein. Die faktorisierten Abstände der
oben zu findenden Wiederholungen sind in der folgenden Tabelle dargestellt.
VQK
:
40
=
5
·
2
·
2
·
2
CZAOY
:
30
=
5
·
3
·
2
OYBZM
:
65
=
13
·
5
BOY
:
50
=
5
·
5
·
2
LOC
:
80
=
5
·
2
·
2
·
2
·
2
RVV
:
25
=
5
·
5
Für
t
erhalten wir
t
=
ggT
(
40, 30, 65, 50, 80, 25
)=
5. Wie wir wissen, ist dies die
tatsächliche Schlüssellänge.
Der Kasiski-Test liefert eine kleine Menge möglicher Schlüssellängen, nämlich
die Teiler von
t
. Der folgende
Friedman-Test
liefert eine Schätzung der Größen-
ordnung der Schlüssellänge
. Kombiniert man die beiden Tests, so erhält man in
den meisten Fällen den genauen Wert von
. Und hat man erst einmal die Schlüs-
sellänge
, so ist es leicht, den Geheimtext zu entschlüsseln, weil man damit die
Verschlüsselung auf
Caesar-Chiffrierungen zurückgeführt hat.
(
)
i
∈
Z
q
Der Friedman-Test.
Dieser Test basiert auf der Häufigkeitsverteilung
h
i
q
über dem Alphabet
aller Buchstaben eines Geheimtextes
C
=
x
1
···
x
n
∈
Z
Z
q
.
Wir gehen vorab davon aus, dass wir irgendeinen Text (sprich einen String)
x
=
n
···
∈
Z
(
)
∈
Q
x
1
x
n
q
vorliegen haben, und erklären zu diesem Text eine Größe
I
x
- den
Friedman'schen Koinzidenzindex
.
Die Zahl
h
a
:
=
|{
=
}|
∈
Z
q
, gibt an, wie oft der Buchstabe
a
im Text
k
;
x
k
a
,
a
x
=
x
1
···
x
n
vorkommt. Die rationale Zahl
1
)
∑
a
(
)
=
(
−
)
I
x
:
h
a
h
a
1
(
−
n
n
1
∈
Z
q
heißt der
(Friedman'sche) Koinzidenzindex
des Wortes
x
. Wir begründen: