Database Reference
In-Depth Information
Creating the ETL
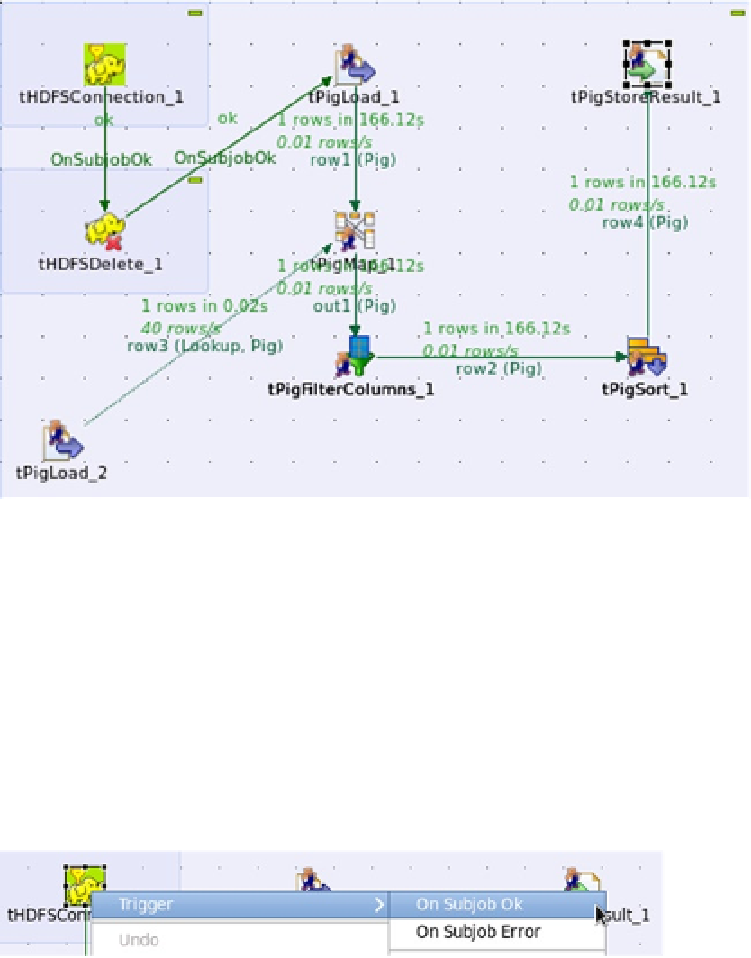
Examining a completed job is a good way to understand Open Studio's modules and workflow. Figure
10-27
shows
job tmr1, the Pig-based Map Reduce job I created for this example. It starts with a connection to HDFS called
tHDFSConnection_1, on the condition that the connection works control is passed to an HDFS delete step called
tHDFSDelete_1, which clears the results directory for the job. If that is okay, then control is passed to a tPigLoad step
called tPigLoad_1, which loads the rawdata.txt file from HDFS. At the same time, another load step called tPigLoad_2
loads the rawprices.txt file from HDFS. The data from these files is then passed to a module called tPigMap_1, which
will combine the data.
Figure 10-27.
Work flow for Pig native Map Reduce job
Figure
10-27
shows that the tPigMap_1 step combines the data from the two files, while the tPigFilterColumns_1
step removes the column data that is not of interest. The tPigSort_1 step sorts the data, then the tPigStoreResult_1 step
saves the sorted data to HDFS.
To create your own jobs, you select modules in the palette and drag them to the center jobs pane. Then, you
right-click the icons to connect the modules via conditional arrows or arrows that represent data flows (as was
done with Pentaho earlier). Figure
10-28
shows the creation of a conditional flow between steps of a job. If the
tHDFSConnection_1 step works, then control will pass to the deletion step. Figure
10-29
illustrates the creation of a
specific data flow between the tPigLoad_1 and tPigMap_1 steps.
Figure 10-28.
Conditional job flow
Search WWH ::

Custom Search