Database Reference
In-Depth Information
Figure 10-29.
Data flow for Pig Map Reduce job
Now that you have a sense of the job as a whole, take a closer look at how it's put together. From this point,
I walk slowly through the configuration of each step of the tmr1 example job, as well as point out some common
troublespots. At the end, I run the job and display the results from the HDFS results directory.
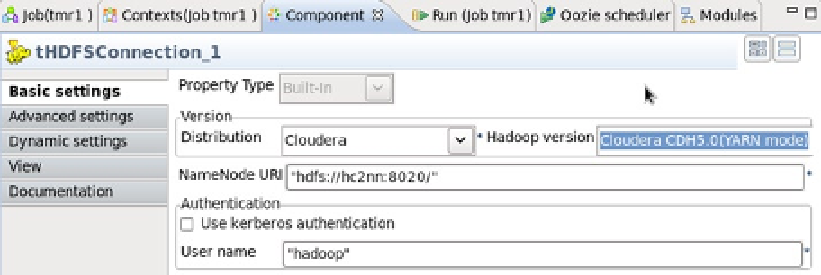
As long as the Component tab in the Designer window is clicked, I can select each step in a job and view its
configuration. For the HDFS connection, for example, the Hadoop version is defined as Cloudera and CDH5. The URI
for the Name Node connection is defined via the cluster Name Node host hc2nn, using the port number 8020. The
user name for the connection is defined as the Linux hadoop account; these choices are shown in Figure
10-30
.
Figure 10-30.
The trm1 job, with HDFS connection
The HDFS delete step shown in Figure
10-31
just deletes the contents of the /data/talend/result/ HDFS directory
so that this Talend job can be rerun. If this succeeds, then control passes to the next step. The ellipses (. . .) button to
the right of the Path field allows me to connect to HDFS and browse for the delete location.
Figure 10-31.
HDFS delete step for trm1 job

Search WWH ::

Custom Search