Graphics Reference
In-Depth Information
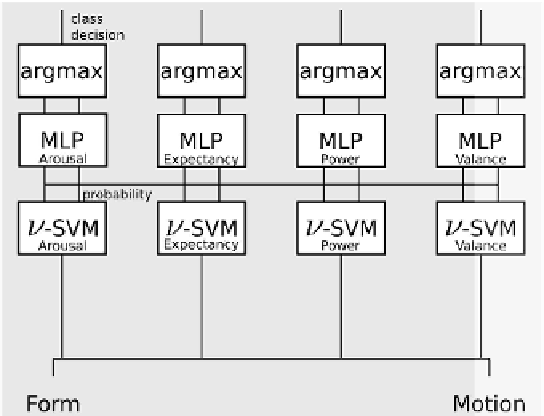
Figure 10.
For the video-based classifi cation, form and motion features are concatenated
and used to train
n
-SVM for each label dimension. The outputs of the classifi ers are used
to train an intermediate fusion layer realized by MLPs.
multiplication. Figure 11 shows the audiovisual classifier system, while
the results are given in Table 3.
4. Conclusion and Future Work
Classifying the emotion is generally a difficult task when leaping from
overacted data to realistic human-computer interaction. In this study,
the problem was investigated by combining different modalities. The
result of the evaluation shows that the usage of different modalities
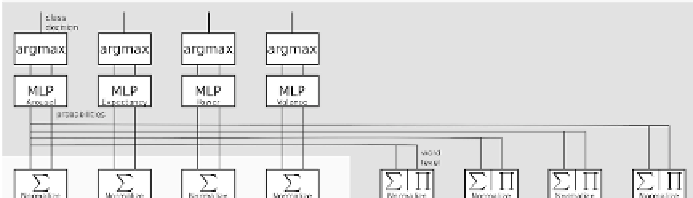
Figure 11.
Overall architecture of the audiovisual classifier system, the outputs of all
modalities are integrated on word level and used to train a multilayer neural network for
each label dimension
.

Search WWH ::

Custom Search