Hardware Reference
In-Depth Information
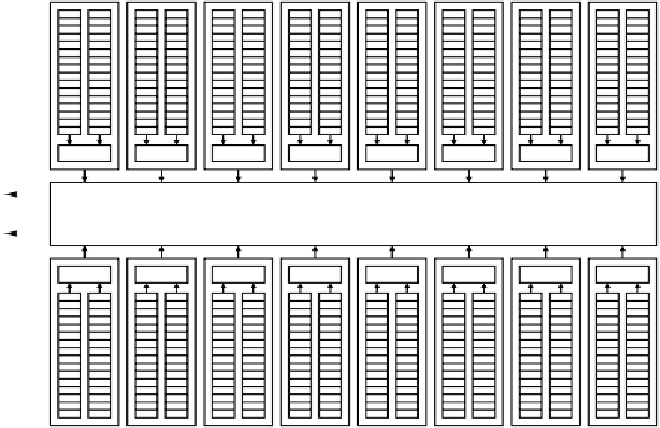
multiprocessors contain 32 CUDA cores, for a total of 512 CUDA cores per Fermi
GPU. A
CUDA
(
Compute Unified Device Architecture
) core is a simple proc-
essor supporting single-precision integer and floating-point computations. A single
SM with 32 CUDA cores is illustrated in Fig. 2-7. The 16 SMs share access to a
single unified 768-KB level 2 cache, which is connected to a multiported DRAM
interface. The host processor interface provides a communication path between
the host system and the GPU via a shared DRAM bus interface, typically through a
PCI-Express interface.
Streaming multiprocessor
CUDA core
Shared mem
To DRAM
L2 cache
To host
interface
Figure 8-17.
The Fermi GPU architecture.
The Fermi architecture is designed to efficiently execute graphics, video, and
image processing codes, which typically have many redundant computations
spread across many pixels. Because of this redundancy, the streaming multiproces-
sors, while capable of executing 16 operations at a time, require that all of the op-
erations executed in a single cycle be identical. This style of processing is called
SIMD
(
Single-Instruction Multiple Data
) computation, and it has the important
advantage that each SM fetches and decodes only a single instruction each cycle.
Only by sharing the instruction processing across all of the cores in an SM can
NVIDIA cram 512 cores onto a single silicon die. If programmers can harness all
of the computation resources (always a very big and uncertain ''if''), then the sys-
tem provides significant computational advantages over traditional scalar architec-
tures, such as the Core i7 or OMAP4430.