Hardware Reference
In-Depth Information
Address
Address
8 Bytes
8 Bytes
24
24
16
8
19
18 17 16
16
8
15 14 13 12 11
10
9
8
15 14 13 12
0
0
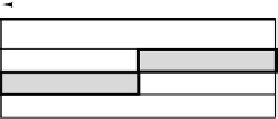
Aligned 8-byte
word at address 8
Nonaligned 8-byte
word at address 12
(a)
(b)
Figure 5-2.
An 8-byte word in a little-endian memory. (a) Aligned. (b) Not
aligned. Some machines require that words in memory be aligned.
program reads a 4-byte word at address 7, the hardware has to make one memory
reference to get bytes 0 through 7 and a second to get bytes 8 through 15. Then the
CPU has to extract the required 4 bytes from the 16 bytes read from memory and
assemble them in the right order to form a 4-byte word. Doing this on a regular
basis does not lead to blinding speed.
Having the ability to read words at arbitrary addresses requires extra logic on
the chip, which makes it bigger and more expensive. The design engineers would
love to get rid of it and simply require all programs to make word-aligned refer-
ences to memory. The trouble is, whenever the engineers say: ''Who cares about
running musty old 8088 programs that reference memory wrong?'' the folks in
marketing have a succinct answer: ''Our customers.''
Most machines have a single linear address space at the ISA level, extending
from address 0 up to some maximum, often 2
32
1 bytes or 2
64
1 bytes. How-
ever, a few machines have separate address spaces for instructions and data, so that
an instruction fetch at address 8 goes to a different address space than a data fetch
at address 8. This scheme is more complex than having a single address space, but
it has two advantages. First, it becomes possible to have 2
32
bytes of program and
an additional 2
32
bytes of data while using only 32-bit addresses. Second, because
all writes automatically go to data space, it becomes impossible for a program to
accidentally overwrite itself, thus eliminating one source of program bugs. Separat-
ing instruction and data spaces also makes attacks by malware much harder to pull
off because the malware cannot change the program—it cannot even address it.
Note that having separate address spaces for instructions and data is not the
same as having a split level 1 cache. In the former case the total amount of address
space is doubled and reads to any given address yield different results, depending
on whether an instruction or a data word is being read. With a split cache, there is
still just one address space, only different caches store different parts of it.
Yet another aspect of the ISA level memory model is the memory semantics.
It is perfectly natural to expect that a
LOAD
instruction that occurs after a
STORE
instruction and that references the same address will return the value just stored.
−
−