Information Technology Reference
In-Depth Information
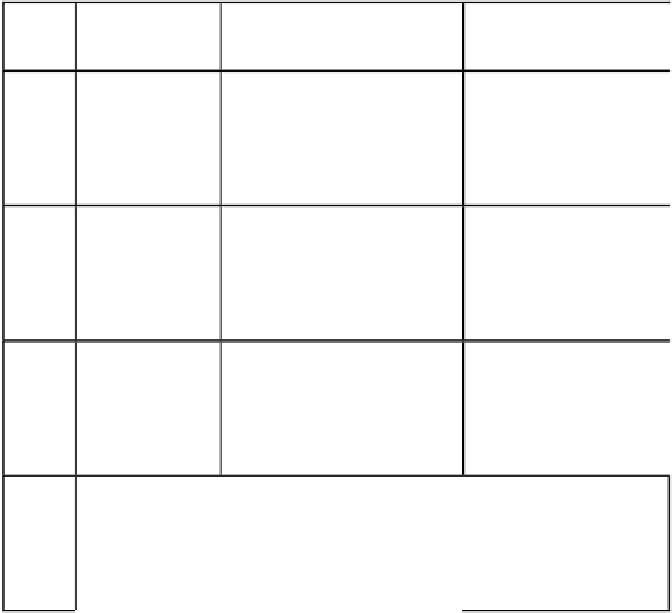
Table 6.3(a).
Training (999 epochs) and evaluation performance of Takagi-Sugeno-type
multi-input single-output neuro-fuzzy network with proposed Levenberg-Marquardt
algorithm for Wang data (second-order nonlinear plant data). Tuning parameter values of
Levenberg-Marquardt algorithm for first model,
i.e
.
M
= 10, GMFs
*
= 10: P = 10, J =
0.01,
mo
= 0.098,
WF
= 1.05; for second model,
i.e
.
M
= 5, GMFs
*
= 5: P = 10, J = 0.01,
mo
= 0.098,
WF
= 1.05
Sl. No.
Input data
SSE & MSE
(with pre-scaled and
non-scaled actual data)
RMSE & MAE
(with pre-scaled and
non-scaled actual data)
1
1-200
Training data
SSE_train = 3.0836e-004
MSE_train = 3.0836e-006
RMSE_train = 0.0018
MAE_train = 0.0012
(
first model
)
Equivalently actual
SSE_train = 0.0012
MSE_ train= 1.1866e-005
Equivalently actual
RMSE_train = 0.0034
MAE_train = 0.0024
2
201-400
Evaluation data
SSE_test = 5.5319e-004
MSE_test = 5.5319e-006
RMSE_test = 0.0024
MAE_test = 0.0015
(
first model
)
Equivalently actual
SSE_test = 0.0021,
MSE_test = 2.1268e-005
Equivalently actual
RMSE_test = 0.0046
MAE_test = 0.0030
3
1-200
Training data
SSE_train = 0.0135
MSE_train = 1.3491e-004
RMSE_train = 0.0116
MAE_train = 0.0087
(
second model
)
Equivalently actual
SSE_train = 0.0519
MSE_train = 5.1866e-004
Equivalently actual
RMSE_train = 0.0228
MAE_train = 0.0170
4
201-400
Evaluation data
SSE_test = 0.0203
MSE_test = 2.0289e-004
RMSE_test = 0.0142
MAE_test = 0.0104
(
second model
)
Equivalently actual
SSE_test = 0.0780
MSE_test = 7.8002e-004
Equivalently actual
RMSE_test = 0.0279
MAE_test = 0.0204
GMFs
*
= Gaussian membership functions
The same experiment was also carried out for
M
= 5 (
second model
), which
exhibited the following training performance with the first 1 to 200 normalized and
scaled training data: SSE and MSE values of 0.0135 and 1.3491×10
-4
respectively,
which correspond to the actual SSE and MSE values of 0.0519 and 5.1866×10
-4
respectively. In addition, as listed below, the testing or evaluation performance of
the Wang data with 201 to 400 rows, for five fuzzy rules and five Gaussian
membership functions has produced SSE and MSE values of 0.0203 and
2.0289×10
-4
respectively. These results further correspond to actual SSE and MSE
values of 0.0780 and 7.8002×10
-4
respectively, which are computed back from
original (non-scaled) evaluation data.


Search WWH ::

Custom Search