Database Reference
In-Depth Information
For classification tasks, there are two measures that can be used to select the best split.
These are Gini impurity and entropy.
Note
See the
MLlib - Decision Tree
section in the
Spark Programming Guide
at
ht-
tp://spark.apache.org/docs/latest/mllib-decision-tree.html
for further details on the de-
cision tree algorithm and impurity measures for classification.
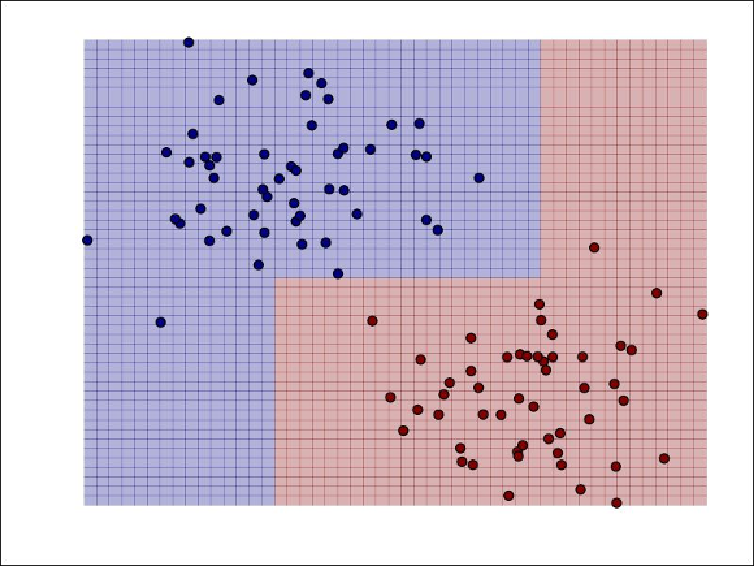
In the following screenshot, we have plotted the decision boundary for the decision tree
model, as we did for the other models earlier. We can see that the decision tree is able to
fit complex, nonlinear models.
Decision function for a decision tree for binary classification