Database Reference
In-Depth Information
Decision trees
Decision tree model is a powerful, nonprobabilistic technique that can capture more com-
plex nonlinear patterns and feature interactions. They have been shown to perform well on
many tasks, are relatively easy to understand and interpret, can handle categorical and nu-
merical features, and do not require input data to be scaled or standardized. They are well
suited to be included in ensemble methods (for example, ensembles of decision tree mod-
els, which are called decision forests).
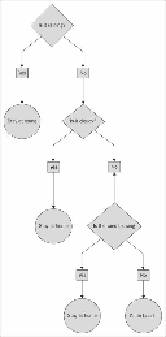
The decision tree model constructs a tree where the leaves represent a class assignment to
class 0 or 1, and the branches are a set of features. In the following figure, we show a
simple decision tree where the binary outcome is
Stay at home
or
Go to the beach
. The
features are the weather outside.
A simple decision tree
The decision tree algorithm is a top-down approach that begins at a root node (or feature),
and then selects a feature at each step that gives the best split of the dataset, as measured by
the information gain of this split. The information gain is computed from the node impurity
(which is the extent to which the labels at the node are similar, or homogenous) minus the
weighted sum of the impurities for the two child nodes that would be created by the split.