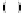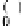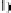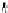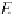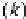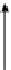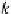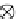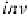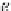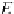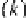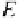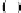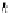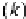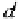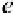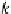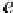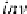Cryptography Reference
In-Depth Information
processing one node at each clock cycle,
α
g
=1
, whereas for a serial architecture,
α
g
=
d
.
Note that in all the GNP architectures presented, we implicitly made the
hypothesis that all the inputs were available and that all the outputs had to
be generated either simultaneously (parallel architecture), or grouped in time
(serial architecture). This kind of GNP control mode is called the "compact
mode".
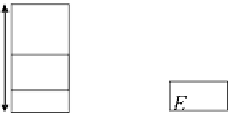
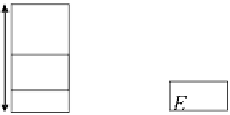
Figure 9.11 - Principle of the distributed mode (delayed update).
It is possible to imagine different execution modes, like the "distributed
mode", in which the GNP inputs and outputs are distributed throughout the
decoding iteration.
Figure 9.11 shows the distributed mode operation of a processor :
•
During the current iteration
n
it
, we consider that the input variables
e
i
come from the previous iteration
n
it
−
1
whereas the output variables
belong to the current iteration.
•
At the end of an iteration, we assume that the
d
input variables
(
e
(
n
it
−
1
i
)
i
=1
..d
are memorized in a memory (internal or external to the
GNP) as well as the value of
E
(
n
it
)
=
e
(
n
it
−
1)
i
⊗
i
=1
..d
.
•
The GNP can therefore, at the request of the system, calculate the
i
-th
output
s
(
n
it
)
i
inv
⊗
(
e
(
n
it
−
1)
i
=
E
(
n
it
)
⊗
)
.
•
This output is sent, via the interleaver, to the opposite node which, once
the computation is over, returns
e
(
n
it
)
i
.
This new value then replaces
e
(
n
it
−
1)
i
•
in the memory and is also accu-
mulated to obtain the value of
E
(
n
it
+1)
at the end of the iteration. Two
accumulation modes are possible: