Information Technology Reference
In-Depth Information
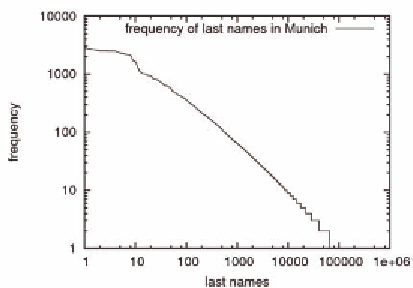
Figure 1. Frequency of last names in Munich,
Germany
INTRODUCTION
Structured peer-to-peer overlay protocols such
as Chord (Stoica et al 2001) are increasingly
used as part of robust and scalable decentralized
infrastructures for communication platforms. For
instance, users connect to an overlay network to
publish their current IP address and port number
using a unique user identifier as the keyword.
In order to establish a communication channel
to a user, the user's identifier must be looked
up in order to learn the TCP/IP connection data.
Registration and lookup of addresses are realized
using Distributed Hashtables (DHT).
However, users in such applications do not
always know the unique identifier of the person
to be contacted. Therefore, it must be possible to
look up the identifier in a phone-book-like user
directory. When looking up an identifier, the user
might not know all data necessary to start an exact
query. For example, the user might know the last
name of the person to be searched, but not its first
name or address. Moreover, people often are not
willing to fill out all data fields, e.g. the address
of the person to be called. Therefore, the phone
book is required to support range queries, like
queries for all people with a certain last name.
A challenge arises from the non-uniform dis-
tribution of people's names. Figure 1 shows the
frequency of last names in the city of Munich,
Germany. Last names are Pareto-distributed, or
Zipf-distributed, i.e., there are a few last names
that are very common, while most last names are
very rare.
In this article, we propose the use of Extended
Prefix Hash Trees (EPHTs) as a scalable indexing
infrastructure to support range queries on top of
Distributed Hash Tables. The EPHT is evaluated
by using real-world phone book data; experiments
show that our approach enables efficient distrib-
uted phone book applications in a reliable way,
without the need for centralized index servers. A
comparison with related work shows that this has
not been possible using techniques introduced
before.
In the following section, we review related
work and highlight the problems with current
approaches. Then, we present the EPHT algo-
rithm, and compare it with the original Prefix
Hash Tree (PHT) algorithm. Then, we evaluate its
performance by running a series of experiments.
Finally, we summarize our results and show our
conclusions.
RELATED WORK
When entries are stored in a Distributed Hash
Table, the location of an entry is defined by the hash
value of its identifier. A common way to achieve
a uniform distribution of the entries among the
peers in the DHT is to require the hash function
used to calculate the hash value to operate in the
Random Oracle Model (Bellare et al, 1993), i.e.
even if two identifiers differ only in a single Bit,
the hash values of these identifiers are two inde-
pendent uniformly distributed random variables.
While this hash function allows for good bal-
ancing of the data load in a DHT, it makes range
queries very costly. Iterating among a range of
identifiers that are lexicographically next to each
other means addressing nodes in a random order
Search WWH ::

Custom Search