Information Technology Reference
In-Depth Information
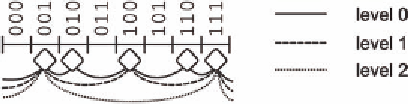
Figure 2. Skip graph
Figure 3. Squid
in the peer-to-peer network. A way to accelerate
range queries is to abandon the Random Oracle
Model, and to store the entries in lexicographical
order. In this section, we discuss three approaches
relying on this idea: Skip Graphs (Aspnes et al,
2003), Squid (Schmidt et al, 2004), and Mercury
(Bharambe et al, 2004). We point out the difficul-
ties arising with these approaches in scenarios like
a distributed phone book.
A comparison between EPHTs and the origi-
nal PHT algorithm (Rambhadran et al, 2004) is
presented after we introduced the EPHT.
Squid
Squid (Schmidt et al, 2004) is an approach for
combining several keywords when determining
the position of an entry in the Distributed Hash
Table. Squid is based on Locality-Preserving Hash-
ing (Indyk et al, 1997), in which adjacent points
in a multi-dimensional domain are mapped to
nearly-adjacent points in a one-dimensional range.
For example, in a distributed phone book appli-
cation, one could use a two-dimensional keyword
domain, where one dimension is the entries' last
name, and the other dimension is the entries' first
name. Figure 3 shows how two dimensions can
be mapped on a one-dimensional range using a
Space Filling Curve (SFC). The SFC passes each
combination of the two identifiers exactly once. If
the user wants to search for all entries with a last
name starting with 'ST' and a first name starting
with 'F', then the user simply needs to query the
parts of the SFC that lie on the intersection of
these two prefixes in the two-dimensional space.
However, as with Skip Graphs, it turns out that
the distribution of names in a phone book results
in combinations that are very common, while
other combinations are very rare. Again, the peers
being responsible for common combinations
become hot spots in terms of data storage and
Skip Graphs
Figure 2 shows a linear three-Bit identifier space.
The peers, as indicated by diamonds, are randomly
distributed among the identifiers. Each peer is re-
sponsible for the identifiers in the range between
itself and its predecessor or successor.
As shown in Figure 2, Skip Graphs introduce
several levels of linked lists for traversing the
peers. The higher the level of the list, the more
peers are skipped, accelerating routing to spe-
cific ranges. By maintaining several independent
lists on each level in parallel, Skip Graphs provide
balancing of the traffic load and resilience to node
failure.
However, the problem with Skip Graphs is
that the entries' identifiers are not distributed
uniformly among the linked list, while the peers
are randomly distributed. Entries for a last name
starting with 'S' are very common in the German
phone book, while last names starting with 'Y'
are very uncommon. Therefore, the peer being
responsible for a common entry becomes a hot
spot in terms of network traffic and data load.

Search WWH ::

Custom Search