Hardware Reference
In-Depth Information
The Advanced Vector Extensions (AVX), added in 2010, doubles the width of the registers
again to 256 bits and thereby offers instructions that double the number of operations on all
narrower data types.
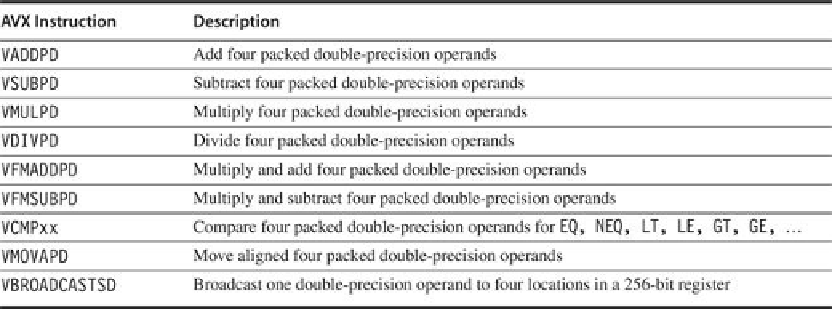
Figure 4.9
shows AVX instructions useful for double-precision loating-
point computations. AVX includes preparations to extend the width to 512 bits and 1024 bits
in future generations of the architecture.
FIGURE 4.9
AVX instructions for x86 architecture useful in double-precision floating-
point programs
. Packed-double for 256-bit AVX means four 64-bit operands executed in
SIMD mode. As the width increases with AVX, it is increasingly important to add data per-
mutation instructions that allow combinations of narrow operands from different parts of the
wide registers. AVX includes instructions that shuffle 32-bit, 64-bit, or 128-bit operands within
a 256-bit register. For example, BROADCAST replicates a 64-bit operand 4 times in an AVX
register. AVX also includes a large variety of fused multiply-add/subtract instructions; we show
just two here.
In general, the goal of these extensions has been to accelerate carefully writen libraries
rather than for the compiler to generate them (see Appendix H), but recent x86 compilers are
trying to generate such code, particularly for floating-point-intensive applications.
Given these weaknesses, why are Multimedia SIMD Extensions so popular? First, they cost
litle to add to the standard arithmetic unit and they were easy to implement. Second, they re-
quire litle extra state compared to vector architectures, which is always a concern for context
switch times. Third, you need a lot of memory bandwidth to support a vector architecture,
which many computers don't have. Fourth, SIMD does not have to deal with problems in vir-
tual memory when a single instruction that can generate 64 memory accesses can get a page
fault in the middle of the vector. SIMD extensions use separate data transfers per SIMD group
of operands that are aligned in memory, and so they cannot cross page boundaries. Another
advantage of short, fixed-length “vectors” of SIMD is that it is easy to introduce instructions
that can help with new media standards, such as instructions that perform permutations or
instructions that consume either fewer or more operands than vectors can produce. Finally,
there was concern about how well vector architectures can work with caches. More recent vec-
tor architectures have addressed all of these problems, but the legacy of past flaws shaped the
skeptical atitude toward vectors among architects.
Search WWH ::

Custom Search