Hardware Reference
In-Depth Information
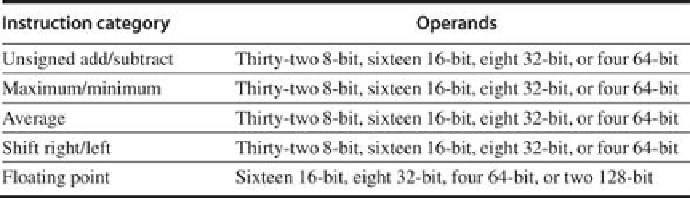
FIGURE 4.8
Summary of typical SIMD multimedia support for 256-bit-wide operations
.
Note that the IEEE 754-2008 floating-point standard added half-precision (16-bit) and quad-
precision (128-bit) floating-point operations.
In contrast to vector architectures, which offer an elegant instruction set that is intended to
be the target of a vectorizing compiler, SIMD extensions have three major omissions:
■ Multimedia SIMD extensions fix the number of data operands in the opcode, which has led
to the addition of hundreds of instructions in the MMX, SSE, and AVX extensions of the
fix architecture. Vector architectures have a vector length register that specifies the num-
ber of operands for the current operation. These variable-length vector registers easily ac-
commodate programs that naturally have shorter vectors than the maximum size the archi-
tecture supports. Moreover, vector architectures have an implicit maximum vector length
in the architecture, which combined with the vector length register avoids the use of many
opcodes.
■ Multimedia SIMD does not offer the more sophisticated addressing modes of vector archi-
tectures, namely strided accesses and gather-scater accesses. These features increase the
number of programs that a vector compiler can successfully vectorize (see
Section 4.7
)
.
■ Multimedia SIMD usually does not offer the mask registers to support conditional execu-
tion of elements as in vector architectures.
These omissions make it harder for the compiler to generate SIMD code and increase the dii-
culty of programming in SIMD assembly language.
For the x86 architecture, the MMX instructions added in 1996 repurposed the 64-bit loating-
point registers, so the basic instructions could perform eight 8-bit operations or four 16-bit
operations simultaneously. These were joined by parallel MAX and MIN operations, a wide
variety of masking and conditional instructions, operations typically found in digital signal
processors, and ad hoc instructions that were believed to be useful in important media librar-
ies. Note that MMX reused the floating-point data transfer instructions to access memory.
The Streaming SIMD Extensions (SSE) successor in 1999 added separate registers that were
128 bits wide, so now instructions could simultaneously perform sixteen 8-bit operations,
eight 16-bit operations, or four 32-bit operations. It also performed parallel single-precision
floating-point arithmetic. Since SSE had separate registers, it needed separate data transfer in-
structions. Intel soon added double-precision SIMD floating-point data types via SSE2 in 2001,
SSE3 in 2004, and SSE4 in 2007. Instructions with four single-precision floating-point opera-
tions or two parallel double-precision operations increased the peak floating-point perform-
ance of the x86 computers, as long as programmers place the operands side by side. With each
generation, they also added ad hoc instructions whose aim is to accelerate specific multimedia
functions perceived to be important.
Search WWH ::

Custom Search