Hardware Reference
In-Depth Information
Increasing Instruction Fetch Bandwidth
A multiple-issue processor will require that the average number of instructions fetched every
clock cycle be at least as large as the average throughput. Of course, fetching these instructions
requires wide enough paths to the instruction cache, but the most difficult aspect is handling
branches. In this section, we look at two methods for dealing with branches and then discuss
how modern processors integrate the instruction prediction and prefetch functions.
Branch-Target Buffers
To reduce the branch penalty for our simple five-stage pipeline, as well as for deeper pipelines,
we must know whether the as-yet-undecoded instruction is a branch and, if so, what the next
program counter (PC) should be. If the instruction is a branch and we know what the next
PC should be, we can have a branch penalty of zero. A branch-prediction cache that stores
the predicted address for the next instruction after a branch is called a
branch-target buffer
or
branch-target cache
.
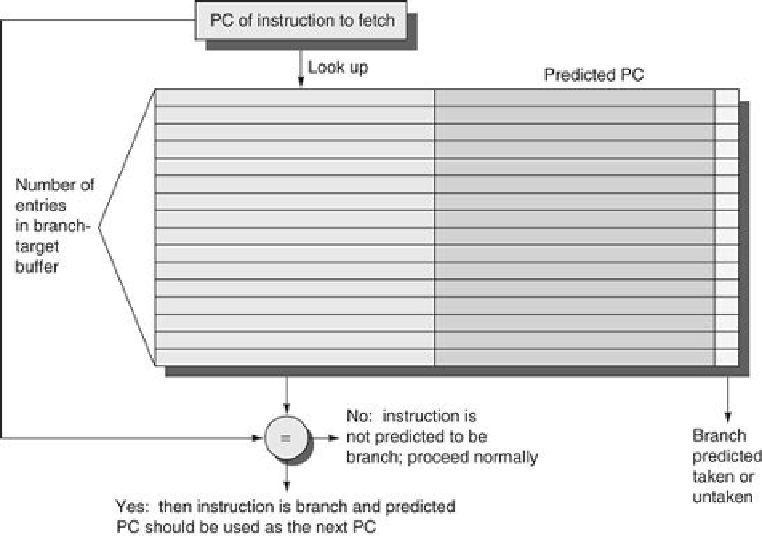
Figure 3.21
shows a branch-target buffer.
FIGURE 3.21
A branch-target buffer
. The PC of the instruction being fetched is matched
against a set of instruction addresses stored in the first column; these represent the ad-
dresses of known branches. If the PC matches one of these entries, then the instruction being
fetched is a taken branch, and the second field, predicted PC, contains the prediction for the
next PC after the branch. Fetching begins immediately at that address. The third field, which
is optional, may be used for extra prediction state bits.
Search WWH ::

Custom Search