Hardware Reference
In-Depth Information
Basics Of Memory Hierarchies: A Quick Review
The increasing size and thus importance of this gap led to the migration of the basics of
memory hierarchy into undergraduate courses in computer architecture, and even to courses
in operating systems and compilers. Thus, we'll start with a quick review of caches and their
operation. The bulk of the chapter, however, describes more advanced innovations that attack
the processor-memory performance gap.
When a word is not found in the cache, the word must be fetched from a lower level in the
hierarchy (which may be another cache or the main memory) and placed in the cache before
continuing. Multiple words, called a
block
(or
line
), are moved for efficiency reasons, and be-
cause they are likely to be needed soon due to spatial locality. Each cache block includes a
tag
to indicate which memory address it corresponds to.
A key design decision is where blocks (or lines) can be placed in a cache. The most popular
scheme is
set associative
, where a
set
is a group of blocks in the cache. A block is first mapped
onto a set, and then the block can be placed anywhere within that set. Finding a block con-
sists of first mapping the block address to the set and then searching the set—usually in paral-
lel—to find the block. The set is chosen by the address of the data:
If there are
n
blocks in a set, the cache placement is called
n-way set associative
. The end points
of set associativity have their own names. A
direct-mapped
cache has just one block per set (so
a block is always placed in the same location), and a
fully associative
cache has just one set (so
a block can be placed anywhere).
Caching data that is only read is easy, since the copy in the cache and memory will be
identical. Caching writes is more difficult; for example, how can the copy in the cache and
memory be kept consistent? There are two main strategies. A
write-through
cache updates the
item in the cache
and
writes through to update main memory. A
write-back
cache only updates
the copy in the cache. When the block is about to be replaced, it is copied back to memory.
Both write strategies can use a
write buffer
to allow the cache to proceed as soon as the data are
placed in the buffer rather than wait the full latency to write the data into memory.
One measure of the benefits of different cache organizations is miss rate.
Miss rate
is simply
the fraction of cache accesses that result in a miss—that is, the number of accesses that miss
divided by the number of accesses.
To gain insights into the causes of high miss rates, which can inspire beter cache designs,
the three Cs model sorts all misses into three simple categories:
■
Compulsory
—The very first access to a block
cannot
be in the cache, so the block must be
brought into the cache. Compulsory misses are those that occur even if you had an ininite
sized cache.
■
Capacity
—If the cache cannot contain all the blocks needed during execution of a program,
capacity misses (in addition to compulsory misses) will occur because of blocks being dis-
carded and later retrieved.
■
Conlict
—If the block placement strategy is not fully associative, conflict misses (in addition
to compulsory and capacity misses) will occur because a block may be discarded and later
retrieved if multiple blocks map to its set and accesses to the different blocks are inter-
mingled.
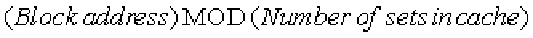
Search WWH ::

Custom Search