Java Reference
In-Depth Information
The program prompts the user to enter a URL string (line 6) and creates a
URL
object (line 9).
The constructor will throw a
java.net.MalformedURLException
(line 19) if the URL
isn't formed correctly.
The program creates a
Scanner
object from the input stream for the URL (line 11). If the
URL is formed correctly but does not exist, an
IOException
will be thrown (line 22). For
exist. An
IOException
would be thrown if this URL was used for this program.
MalformedURLException
12.38
✓
✓
How do you create a
Scanner
object for reading text from a URL?
Check
Point
This case study develops a program that travels the Web by following hyperlinks.
Key
Point
The World Wide Web, abbreviated as WWW, W3, or Web, is a system of interlinked hyper-
text documents on the Internet. With a Web browser, you can view a document and follow
the hyperlinks to view other documents. In this case study, we will develop a program that
automatically traverses the documents on the Web by following the hyperlinks. This type of
program is commonly known as a
Web crawler
. For simplicity, our program follows for the
hyperlink that starts with
http://
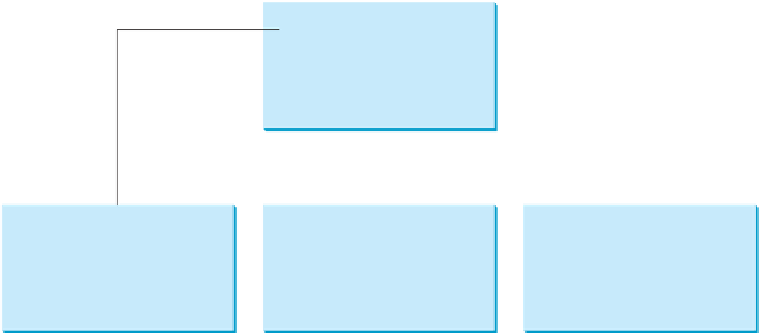
. Figure 12.11 shows an example of traversing the Web.
We start from a Web page that contains three URLs named
URL1
,
URL2
, and
URL3
. Following
URL1
leads to the page that contains three URLs named
URL11
,
URL12
, and
URL13
. Follow-
ing
URL2
leads to the page that contains two URLs named
URL21
and
URL22
. Following
URL3
leads to the page that contains four URLs named
URL31
,
URL32
, and
URL33
, and
URL34
.
Continue to traverse the Web following the new hyperlinks. As you see, this process may
continue forever, but we will exit the program once we have traversed 100 pages.
Web crawler
Starting URL
URL1
URL2
URL3
URL1
URL2
URL3
URL11
URL21
URL31
URL12
URL22
URL32
URL13
URL33
URL4
…… …
…
…
…………
F
IGURE
12.11
The client retrieves files from a Web server.
The program follows the URLs to traverse the Web. To ensure that each URL is traversed
only once, the program maintains two lists of URLs. One list stores the URLs pending for
traversing and the other stores the URLs that have already been traversed. The algorithm for
this program can be described as follows:
Add the starting URL to a list named listOfPendingURLs;
while listOfPendingURLs is not empty and size of listOfTraversedURLs
<= 100 {































Search WWH ::

Custom Search