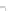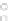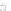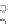Information Technology Reference
In-Depth Information
1
x
2
0.5
0
−0.5
x
1
−1
−1
−0.5
0
0.5
1
Fig. 2.10 A 500 instances per class sample distributed according to expressions
(2.49) and (2.50), for
a
=0
.
9
,b
=
−
1
,c
=1
(class
ω
1
in gray).
The solutions can be simply described by the angle
α
such that
x
2
=
x
1
tan
α
. For every
α
the error density can be obtained by first deriving
the density of the classifier output. The theoretical Shannon EE and MSE
(variance,
V
,since
f
E
(
e
) is symmetric around the origin) are easily computed
for two configurations:
•
Configuration with
α
=
−π/
2
,ϕ
(
x
) =
−x
1
(the min
P
e
solution):
1
2
ln(1
a
)+
1
ln
1
4
H
S
=
−
2
ln(
a
−
b
)
−
;
(2.51)
a
)
2
b
)
2
24
b
)
2
(1
−
+
(
a
−
+
(2
−
a
−
V
=
.
(2.52)
6
8
•
Configuration with
α
=0
,ϕ
(
x
) =
x
2
:
ln
1
2
H
S
=ln
c
−
;
(2.53)
c
2
12
+1
.
V
=
(2.54)
For this family of datasets, MEE and MMSE do not always pick from
ϑ
the
correct solution (the vertical line at
α
=
π/
2). Let us first restrict ourselves
to the two configurations above (the classifier must either select the
α
=
−
π/
2
or the
α
=0straight line). When a method picks the right solution let us
call that a “win”, otherwise let us call that a “loss”.
Figure 2.11 shows subsets of the (
a, b
) space for two values of
c
(using the
above formulas). We see that for both
c
values there are subsets in the (
a, b
)
space where MEE wins and MMSE loses. Such subsets can be found for every
c
.
−