Biology Reference
In-Depth Information
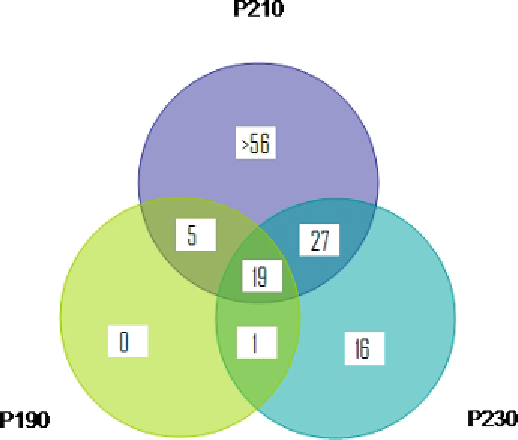
Fig. 4.8.
Distribution of the significantly downregulated genes across P190, P210,
and P230.
data are rarely of direct benefit. Its true value is predicated on the ability
to extract information useful for decision support or for exploration and
understanding of the phenomenon governing the data source. In the
microarray domain, data analysis was traditionally a manual process. One
or more analysts would become intimately familiar with the data and, with
the help of statistical techniques, provide summaries and generate reports.
However, such an approach rapidly broke down as the volume of data
grew and the number of dimensions increased. When the scale of data
manipulation and exploration goes beyond human capacities, people need
the aid of computing technologies for automating the process. This has
therefore prompted the need for intelligent data analysis methodologies,
which could discover useful knowledge from data.
Classification is also described as supervised learning (Tou and
Gonzalez, 1974). Classification and clustering are two data mining tasks
with close relationships. A class is a set of data samples with some simi-
larity or relationship, and all samples in one class are assigned the same

Search WWH ::

Custom Search