Database Reference
In-Depth Information
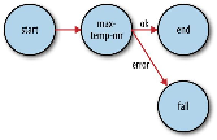
Figure 6-4. Transition diagram of an Oozie workflow
All workflows must have one
start
and one
end
node. When the workflow job starts, it
transitions to the node specified by the
start
node (the
max-temp-mr
action in this
example). A workflow job succeeds when it transitions to the
end
node. However, if the
workflow job transitions to a
kill
node, it is considered to have failed and reports the
appropriate error message specified by the
message
element in the workflow definition.
The bulk of this workflow definition file specifies the
map-reduce
action. The first two
elements,
job-tracker
and
name-node
, are used to specify the YARN resource
manager (or jobtracker in Hadoop 1) to submit the job to and the namenode (actually a
Hadoop filesystem URI) for input and output data. Both are parameterized so that the
workflow definition is not tied to a particular cluster (which makes it easy to test). The
parameters are specified as workflow job properties at submission time, as we shall see
later.
WARNING
Despite its name, the
job-tracker
element is used to specify a YARN resource manager address and
port.
The optional
prepare
element runs before the MapReduce job and is used for directory
deletion (and creation, too, if needed, although that is not shown here). By ensuring that
the output directory is in a consistent state before running a job, Oozie can safely rerun the
action if the job fails.
The MapReduce job to run is specified in the
configuration
element using nested
elements for specifying the Hadoop configuration name-value pairs. You can view the
MapReduce configuration section as a declarative replacement for the driver classes that
we have used elsewhere in this topic for running MapReduce programs (such as
Example 2-5
)
.
We have taken advantage of JSP Expression Language (EL) syntax in several places in the
workflow definition. Oozie provides a set of functions for interacting with the workflow.