Java Reference
In-Depth Information
with before you move on, though, is the data model. That will help clear the air regarding how this
system is structured. Let's take a look.
Understanding the Data Model
You've seen all the different pieces of the job you create throughout this topic. Let's move on to the last
piece of the puzzle before you get into actual development. Batch processes are data driven. Because
there are no user interfaces, the various datastores end up being the only external interaction the
process has. This section looks at the data model used for the sample application.
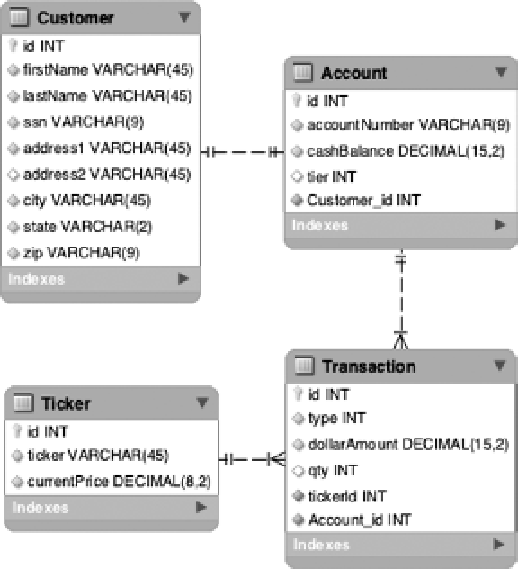
Figure 3-4 outlines the application-specific tables for this batch process. To be clear, this diagram
doesn't encompass all the tables required for this batch job to run. Chapter 2 took a brief look at the
tables Spring Batch uses in the job repository. All of those tables will exist in addition to these in your
database. Because it isn't uncommon to deploy the batch schema separately, and you reviewed it in the
last chapter, I've chosen to leave it out of Figure 3-4.
Figure 3-4.
Sample application data model
For the batch application, you have four tables: Customer, Account, Transaction, and Ticker. When
you look at the data in the tables, notice that you aren't storing all the required fields to generate the
statement. There are fields (such as the totals in the account summary) that you calculate during
processing. Other than that, the data model should appear relatively straightforward:
•
Customer:
This record contains all the customer-specific information, including
name and tax identification number.