Information Technology Reference
In-Depth Information
This chapters begins with a general overview of the problems that were the
prime motivator for the development of LCS. This is followed by a review of
the ideas behind LCS, describing the motivation and structure of Holland's first
LCS, the CS-1 [116]. Many of the LCS that followed had a similar structure
and so instead of describing them in detail, Sect. 2.2.5 focuses on some of the
problems that they struggled with. With the introduction of XCS [237] many of
these problems disappeared and the role of the classifier within the population
was redefined, as discussed in Sect. 2.3. However, as our theoretical understan-
ding even of XCS is still insucient, and as this work aims at advancing the
understanding of XCS and LCS in general, Sect. 2.4 gives an overview over re-
cent significant approaches to the theoretical analysis of LCS, before Sect. 2.5
puts the model-based design approach into the general LCS context.
2.1
A General Problem Description
Consider an agent that interacts with an environment. At each discrete time
step the environment is in a particular
hidden state
that is not observable by the
agent. Instead, the agent senses the
observable state
of the environment that is
stochastically determined by its hidden state. Based on this observed state, the
agent performs an action that changes the hidden state of the environment and
consequently also the observable state. The hidden state transitions conform to
the Markov property, such that the current hidden state is completely determined
s
t
+1
s
t
s
t
+1
s
t
r
t
o
t
a
t
b
t
+1
b
t
a
t
r
t
(a)
(b)
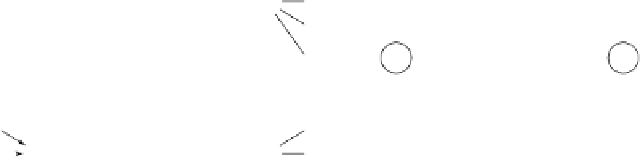
Fig. 2.1.
The variables of a POMDP and an MDP involved in a single state transition
from state
s
t
to state
s
t
+1
after the agent performs action
a
t
and receives reward
r
t
. Each node represents a random variable, and each arrow indicates a dependency
between two variables. (a) shows the transition in a POMDP, where the state
s
t
is
hidden from the agent which observes
o
t
instead. The agent's action depends on the
agent's belief
b
t
about the real state of the environment and the currently observed state
o
t
. Based on this action and the environment's hidden state, a reward
r
t
is received and
the environment performs a transition to the next state
s
t
+1
. Additionally, the agent
update its belief
b
t
+1
, based on the observed state
o
t
. (b) shows the same transition in
an MDP where the agent can directly observe the environment's state
s
t
,andperforms
action
a
t
based on that. This causes the agent to receive reward
r
t
and the environment
to perform a state transition to
s
t
+1
.























Search WWH ::

Custom Search