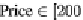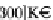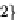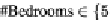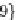Database Reference
In-Depth Information
Figure 5. Example of hierarchical categorization of query results
The order in which the attributes appear in the tree, and the values used to split the domain of any
attribute are inferred by analyzing the aggregate knowledge of previous user behaviors - using the
workload. Indeed, the attributes that appear most frequently in the workload are presented to the user
earlier (i.e., at the highest levels of the tree). The intuition behind this approach is that the presence of
a selection condition on an attribute in a workload reflects the user's interest in that attribute. Further-
more, for each attribute
A
i
, one of the following two methods is used to partition the set of tuples
tset(C)
contained in a category
C
depending on whether
A
i
is categorical or numeric:
•
If
A
i
is a categorical attribute with discrete values
{v
1
,…, v
k
}
, the proposed algorithm simply parti-
tions
tset(C)
into
k
categories, one category
C
j
corresponding to a value
v
j
. Then, it presents them
in the decreasing order of
occ(A
i
= v
j
)
, i.e., the number of queries in the workload whose selection
condition on
A
i
overlaps with
A
i
= v
j
;
•
Otherwise, assume the domain of attribute
A
i
is the interval
[v
min
, v
max
]
. If a significant number of
query ranges (corresponding to the selection condition on
A
i
) in the workload begins or ends at
v[v
min
, v
max
]
, then
v
is considered as a good point to split
[v
min
, v
max
]
. The intuition here is that most
users would be interested in just one bucket, i.e., either in the bucket
A
i
≤ v
or in the bucket
A
i
>
v
but not both.
This approach provides the user with navigational facilities to browse query results. However, it re-
quires a workload containing past user queries as input, which is not always available. Furthermore, the
hierarchical category structure is built at query time, and hence the user has to wait a long time before
the results can be displayed.
OSQR
In Bamba, Roy & Mohania (2005), the authors proposed OSQR
xiii
, an approach for clustering database
query results based on the agglomerative single-link approach (Jain, Murty & Flynn, 1999). Given an
SQL query as input, OSQR explores its result set, and identifies a set of terms (called the query's context)
that are the most relevant to the query; each term in this set is also associated with a score quantifying