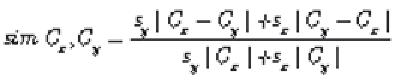Database Reference
In-Depth Information
its relevance. Next, OSQR exploits the term scores and the association of the rows in the query result
with the respective terms to define a similarity measure between the terms. This similarity measure
is then used to group multiple terms together; this grouping, in turn, induces a clustering of the query
result rows. More precisely, consider a query
q
on a table
R
, and let
T
q
denote the result of the query
q
.
OSQR works as follows:
1. scan
T
q
and assign a score
s
x
to each attribute value
x
(or term) in
T
q
. The terms' scores (similar to
tf * idf
scores used in information retrieval) are defined in such a way that higher scores indicate
attributes values that are popular in the query result
T
q
and are rare in
R-T
q
;
2. compute the context of
q
as the set of terms
q
context
with scores exceeding a certain threshold (a
system parameter);
3. associate to each term
x
in
q
context
the cluster
C
x
, i.e., the set of tuples of
T
q
in which the attribute
value
x
appears. The tuples in
T
q
that are not associated with any term
xq
context
are termed 'outliers'.
These rows are not processed any further; iteratively merge the two most similar clusters until a
stopping condition is met. The similarity
sim(C
x
,C
y
)
between each pair of clusters
C
x
and
C
y
(
x
,
y
q
context
)
is defined as follows:
where |.| denotes the cardinality of a set.
OSQR's output is a dendrogram that can be browsed from its root node to its leaves, where each leaf
represents a single term
x
in
q
context
and its associated tuple set
C
x
.
The above approach has many desirable features: it generates overlapping clusters, associates a de-
scriptive 'context' with each generated cluster, and does not require the query workload. However, note
that some query results (tuples that are not associated with any term in
q
context
) are ignored and therefore
not included in the output result. Moreover, this approach may imply high response times, especially in
the case of low selectivity queries, since both scoring and clustering of terms are done on the fly.
Li et al's System
In a recent work (Li, Wang, Lim, Wang & Chang, 2007), the authors generalized the SQL group-by
operator to enable grouping (based on the proximity of attribute values) of database query results. Con-
sider a relation
R
with attributes
A
1
,…,A
N
and a user's query
q
over
R
with a group-by clause on a subset
X
of
R
's numeric attributes. The proposed algorithm first divides the domain of each attribute
A
i
X
into
p
i
disjoint intervals (or bins) to form a grid of
p
Õ
buckets (or cells). Next, this approach identifies
the set of buckets
C = {b
1
,…, b
m
}
that holds the results of
q
, and associates to each bucket
b
i
a virtual
point
v
i
, located at the center of that bucket. Finally, a
k
-means algorithm is performed on these virtual
points (i.e.,
{v
1
,…, v
m
}
) to obtain exactly
k
clusters of q's results. The
k
parameter is given by the en-
duser. For example, consider a user's query that returns 10 tuples
t
1
,…, t
10
and the user needs to partition
these tuples into 2 clusters, using two attributes
A
1
and
A
2
. Figure 6 shows an example of a grid over
t
1
,…, t
10
by partitioning attributes
A
1
and
A
2
. The bins on
A
1
and
A
2
are {[0, 3), [3, 6), [6, 9)} and {[0,
10), [10, 20), [20, 30)}, respectively. The two clusters
C
1
(i.e.
A
1
[0, 3]
A
2
[10, 30]) and
C
2
(i.e.,
A
1
[6,