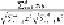Database Reference
In-Depth Information
As
d
grows, the denominator grows linearly in
d
, but the numerator is a sum of random
values, which are as likely to be positive as negative. Thus, the expected value of the nu-
merator is 0, and as
d
grows, its standard deviation grows only as Thus, for large
d
, the
cosine of the angle between any two vectors is almost certain to be close to 0, which means
the angle is close to 90 degrees.
An important consequence of random vectors being orthogonal is that if we have three
random points
A
,
B
, and
C
, and we know the distance from
A
to
B
is
d
1
, while the distance
from
B
to
C
is
d
2
, we can assume the distance from
A
to
C
is approximately That rule
does not hold, even approximately, if the number of dimensions is small. As an extreme
case, if
d
= 1, then the distance from
A
to
C
would necessarily be
d
1
+
d
2
if
A
and
C
were
on opposite sides of
B
, or |
d
1
−
d
2
| if they were on the same side.
7.1.4
Exercises for Section 7.1
!
EXERCISE
7.1.1 Prove that if you choose two points uniformly and independently on a
line of length 1, then the expected distance between the points is 1/3.
!!
EXERCISE
7.1.2 If you choose two points uniformly in the unit square, what is their ex-
pected Euclidean distance?
!
EXERCISE
7.1.3 Suppose we have a
d
-dimensional Euclidean space. Consider vectors
whose components are only +1 or −1 in each dimension. Note that each vector has length
so the product of their lengths (denominator in the formula for the cosine of the angle
between them) is
d
. If we chose each component independently, and a component is as
likely to be +1 as −1, what is the distribution of the value of the numerator of the formula
(i.e., the sum of the products of the corresponding components from each vector)? What
can you say about the expected value of the cosine of the angle between the vectors, as
d
grows large?
7.2 Hierarchical Clustering
We begin by considering hierarchical clustering in a Euclidean space. This algorithm can
only be used for relatively small datasets, but even so, there are some efficiencies we can
make by careful implementation. When the space is non-Euclidean, there are additional