Database Reference
In-Depth Information
Configuring attribute relationships
Attribute relationships allow you to model one-to-many relationships between
attributes. For example, you might have
Year
,
Month
, and
Date
attributes on your
Time
dimension, and you know that there are one-to-many relationships between
Year
and
Month
, and
Month
and
Date
, so you should build the attribute relationships between
these three attributes to reflect this. Why? The short answer is performance. Setting
attribute relationships optimally can make a very big difference to query performance,
and the importance of this cannot be overstated—they drastically improve Analysis
Services' ability to build efficient indexes and make use of aggregations. However,
attribute relationships do not have anything to do with how the dimension gets
displayed to the end user, so don't get them confused with user hierarchies.
It's very likely that there will be many different ways to model attribute relationships
between the same attributes in a dimension, so the important thing is to find the best
way of modeling the relationships from a performance point of view. When you first
build a dimension in SSDT, you will get a set of attributes relationships that while
correct, are not necessarily optimal. This default set of relationships can be described
as looking a bit like a bush. Every non-key attribute has a relationship defined either
with the key attribute, or with the attribute built on the primary key of the source table
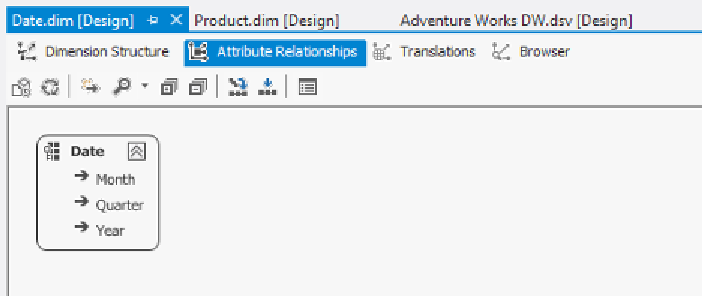
in a snowflaked dimension. You can visualize these relationships on the
Attribute
Relationships
tab of the Dimension Editor, as shown in the following screenshot:

Search WWH ::

Custom Search