Database Reference
In-Depth Information
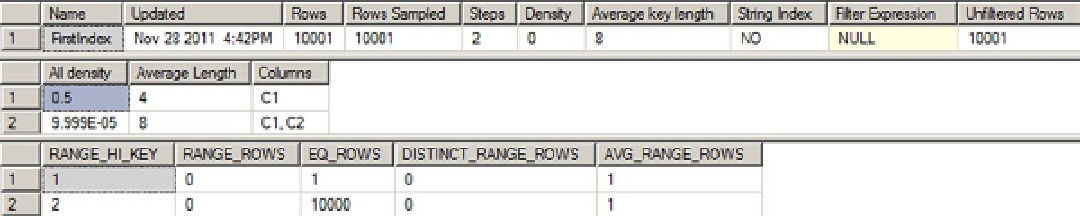
As you can see, instead of adding a single statistic with multiple columns, two new statistics were created. You
will get a multicolumn statistic only in a multicolumn index key or with manually created statistics.
To better understand the density values maintained for a multicolumn index, you can modify the nonclustered
index used earlier to include two columns.
CREATE NONCLUSTERED INDEX FirstIndex
ON dbo.Test1(C1,C2) WITH DROP_EXISTING = ON;
Figure
12-22
shows the resultant statistics provided by
DBCC SHOWSTATISTICS
.
Figure 12-22.
Statistics on the multicolumn index FirstIndex
As you can see, there are two density values under the
All density
column.
The density of the first column
•
•
The density of the (first + second) columns
For a multicolumn index with three columns, the statistics for the index would also contain the density value of
the (first + second + third) columns. The histogram won't contain a selectivity values for any other combination of
columns. Therefore, this index (
FirstIndex
) won't be very useful for filtering rows only on the second column (
C2
),
because that value of the second column (
C2
) alone isn't maintained in the histogram.
You can compute the second density value (0.000099990000) shown in Figure
12-19
through the following steps.
This is the number of distinct values for a column combination of (
C1
,
C2
).
SELECT 1.0 / COUNT(*)
FROM (SELECT DISTINCT
C1,
C2
FROM dbo.Test1
) DistinctRows;
Statistics on a Filtered Index
The purpose of a filtered index is to limit the data that makes up the index and therefore change the density
and histogram to make the index perform better. Instead of a test table, this example will use a table from
the
AdventureWorks2012
database. Create an index on the
Sales.PurchaseOrderHeader
table on the
PurchaseOrderNumber
column.
CREATE INDEX IX_Test
ON Sales.SalesOrderHeader (PurchaseOrderNumber);