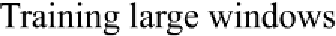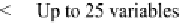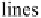Image Processing Reference
In-Depth Information
Figure 4.8
Problems with large window sizes. For larger window sizes, the number of lines in
the table of observations very rapidly becomes extremely large. This means that even the
training data from many thousands of images is spread very thinly throughout the table.
Many inputs will not have been observed a sufficient number of times to make a statistically
robust estimate. Even more inputs will not have been observed at all.
output value. In the examples given in previous chapters, every input was seen many
times. However, as the size of the filter (and hence the table of observations) in-
creases, the table can become very sparse. The observation table for a 25-point win-
dow contains over 33 million lines (see Fig. 4.8). If this were to be trained on a 512 ×
512 image, there would only be a quarter of a million observations to distribute over
33 million lines, and hence most of the counts in the table would be zero. It can now
be seen that the 17-point window is attractive. Despite spanning a similar region of
support, it has only 131,072 possible inputs making it much easier to train on just a
few images. Where a particular input is not seen in the training set, the filter does not
know which value to allocate for its output. If that particular input is encountered in
the actual image to be filtered, the output may be arbitrary leading to large errors.
4.2 Training Errors
Let it be assumed that
ψ
opt
is the optimum filter for a given task. If the filter
ψ
n
is the
best filter that may be implemented within an
n
-point window, then
ψ
n
will be
suboptimal to
ψ
opt
and hence
ψ
n
is a constrained version of
ψ
opt.
If, however, the windowed filter is produced by training on a fixed number of
samples
N
, the resulting filter
ψ
n,N
will be further suboptimal to both
ψ
n
and
ψ
opt.
)
)
(
(
(
)
MAE
ψ
≥
MAE
ψ
≥
MAE
ψ
(4.1)
nN
,
n
opt