Database Reference
In-Depth Information
Fig. 2.1 The training set projected onto a two-dimensional graph.
Fig. 2.2 A decision tree (decision stump) based on a horizontal split.
2.3 Training the Decision Tree
For the sake of simplicity, let us simplify the spam filtering task and assume
that there are only two numeric input attributes. This allows us to project
the training set onto a two-dimensional graph as illustrated in Figure 2.1.
The
-axis
corresponds to the “Email Length”. Each email instance is represented as
a circle. More specifically, spam emails are indicated by a filled circle; ham
emails are marked by an empty circle.
A decision tree divides the space into axis-parallel boxes and associates
each box with the most frequent label in it. It begins by finding the best
horizontal split and the best vertical split (best in the sense of yielding the
lowest misclassification rate). Figure 2.2 presents the best horizontal split
and its corresponding decision tree. Similarly, Figure 2.3 presents the best
vertical split and its corresponding decision tree. A single node decision tree
as presented in Figures 2.2 and 2.3 is sometimes called a Decision Stump.
x
-axis corresponds to the “New Recipients” attribute and the
y












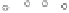































Search WWH ::

Custom Search