configured below their maximum size. Adding disks, controllers, or CPUs will not improve the
performance. They do not use the maximum throughput of either I/O or memory buses.
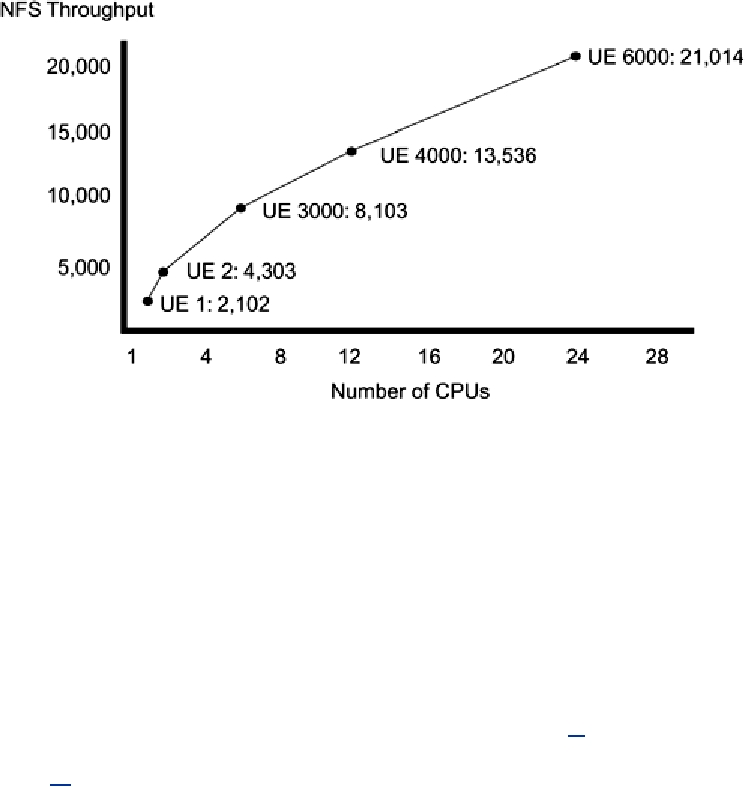
Figure 15-8. NFS Throughput on a Series of Sun UE Machines (The performance
improvement is somewhat exaggerated, as a two-way UE6000 will outperform a
two-way UE 2.)
In all of these maximum performance configurations, the bottleneck is contention and memory
latency. One CPU will be working on some portion of a file system and will have locked inodes,
allocation tables, etc., that another CPU requires. Once these locks are released, the other CPUs
may have to context switch to the appropriate thread. It will certainly have to take a lot of cache
misses to load those newly changed tables. Additional CPUs will not improve the situation, but
higher-performance CPUs will. This is because one CPU can now do more work, hence the data in
cache will be used more, reducing both the number of misses and the amount of contention.
NFS is not a "typical" client/server application in one particular aspect: NFS is started as a typical
user-level process, but all that process does is to make a single call into the kernel. For the rest of
its lifetime, NFS remains in the kernel, spawning threads there as it deems necessary. Thus, NFS
does not have to do any context switching for I/O as normal user-level programs must do, and it
can avoid the extra step of copying data from kernel buffer to user space.[9] NFS could have been
written as a user-level program, but the context switching would have killed performance. It was
[9]
Most programs would not benefit from the "optimization" of executing entirely in the kernel.
Outside the horrible complexity of trying to build and maintain a patched kernel using constantly
changing internal kernel interfaces, very few programs spend so much time in system calls and so
little time in their own code. NFS spends about 45% of its time in the transport layer, 45% in the file
system, and 10% in actual NFS code. Even DBMSs which are known for their enormous I/O
demands pale in comparison to NFS. The distinction is that DBMSs are going to use much of the
data they load, as opposed to just pushing it across the network like NFS.
[10]
There is one example of precisely this being done, but it was never optimized to any degree, so
we can't validly compare the (abysmal) results.
A 24-way ES6000 can sustain about 21,000 NFS operations/second (about 900 ops/CPU) with a
latency of about 40 ms. A one-way machine gets about 2000 ops. This implies a requirement of
500µs on the CPU per NFS op and thus 80 outstanding requests (waiting for the disks) at any one
time. The limiting factor is CPU power plus locking contention. There is plenty of room for more
or faster disks, and more network cards, but they wouldn't help.
Search WWH :