Throughput vs. Latency
Given these resources, we next must refine our definition of performance--do we want to
minimize latency for individual subsystems, such as having an NFS server respond to individual
requests as fast as possible, or do we want to maximize the number of requests per second that the
server can handle? This is a serious consideration and we cannot blithely answer "both."
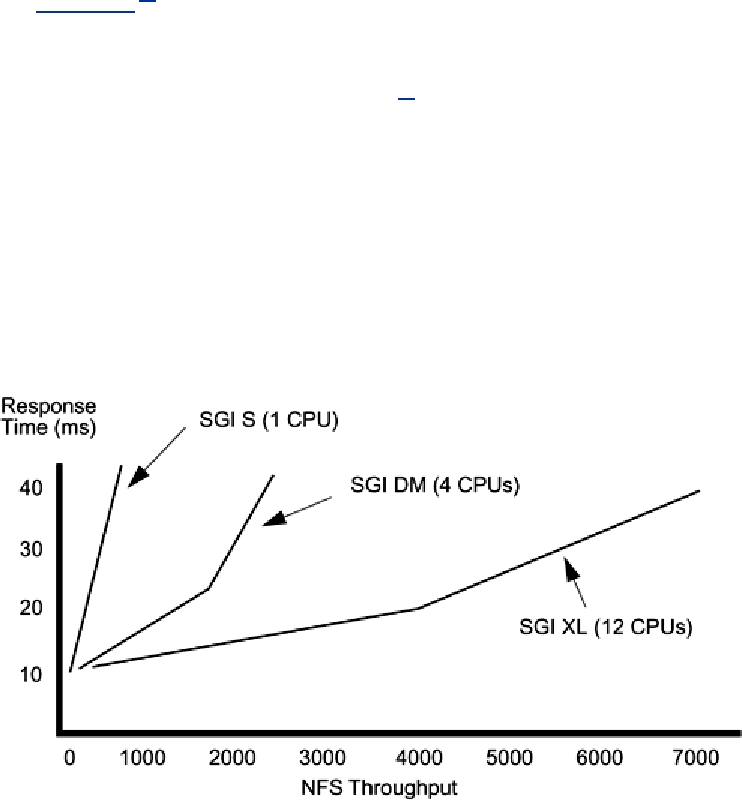
Consider Figure 15-1.[5] We get to select the point on the graph where we wish to operate. For
some programs (e.g., numerical calculations), this latency vs. throughput issue is nonexistent; for
others (e.g., NFS) it is paramount. The answer to the question is almost always, "Maximize
throughput with 'reasonable' latency." For NFS this means that everyone designs their servers to
give maximum throughput at 40-ms average latency.[6] The question now becomes: "For my
individual application, which of these subsystems is the limiting factor, and how much can I
accelerate that before another subsystem becomes saturated?"
[5]
Program data and graphs from Hennessy and Patterson, Computer Architecture, 2nd edition
(San Francisco: Morgan Kauffmann, 1996).
[6]
Forty milliseconds is also the limit chosen for the maximum allowable latency for the SPEC
Laddis benchmark.
Figure 15-1. NFS Throughput vs. Latency on Some SGI Machines
Limits on Speedup
A naive view of multiprocessing says that we should expect a two-CPU machine to do twice as
much work as a one-CPU machine. Empirically, this is not at all the case. Indeed, it is not unusual
to hear reports of people who see very little improvement at all. The truth is that it all depends
upon what you are doing. We can cite examples of programs that get near-linear speedup, a few
that show superlinear speedups, a large majority that show some speed up, and even a few that
slow down.
Search WWH :