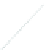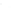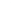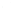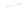Information Technology Reference
In-Depth Information
japanese_plum artemisia
emmental_cheese
lettuce
brussels_sprout
lime_juice
brandy
sturgeon_caviar
potato
vegetable
broccoli
cumin
shallot
mint
roasted_almond
red_kidney_bean
peppermint_oil
pork_liver
pimenta
rapeseed
lobster
kale
lamb
macaroni
asparagus
cheese parmesan_cheese
red_kidney_bean
spearmint
asparagus
barley
rosemary
meat
basil
pork_sausage
sage
cumin
spearmint
fennel
savory
porcini
rosemary
fennel
basil
roasted_almond
roasted_beef
pork_sausage
sage
cheese
savory
lamb
horseradish
kale
parmesan_cheese
macaroni
horseradish
lime_juice
mint
porcini
pimenta
meat
baked_potato
lobster
shallot
lettuce
rapeseed
sturgeon_caviar
baked_potato
potato
broccoli
roasted_beef
barley
artemisia
pork_liver
brandy
vegetable
brussels_sprout
emmental_cheese
peppermint_oil
japanese_plum
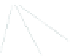
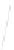
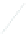
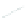
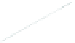
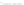
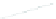
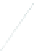
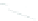
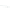
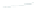
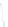
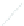
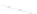
(a) 139 edge crossings
(b) 259 edge crossings
Fig. 1.
A
small dense
graph with 40 vertices and 100 edges constructed from the
Recipes
dataset
with (a) the
low
number of crossings and (b) the
high
number of crossings.
result by automatically generating all ourdrawings, withoutanymanual postprocess-
ing,assuggested in [13, 23]. We emphasize here that unlike most previousstudies, we
work only with real-world graphs and automatically computed layouts.
Ourstudy involves a two-phase evaluation. In the first step (Experiment 1), the par-
ticipant perform simple tasks on several graphs with different sizes (number of vertices)
and densities (ratio of number of edges to number of vertices). This is how we deter-
mine the size of the largest graphs for which task accuracy is steadily above 50%.We
use the information to design the main experiment (Experiment 2) in which we record
performance, in terms of accuracy and completion time for ourfourtasks.
Datasets and Visualization.
In order to minimize potential bias, we use two different
datasets in ourevaluation. The
Recipes
dataset contains 381 uniqueingredients ex-
tracted from cooking recipes. The edges correspond to co-occurrence of the ingredients
in the recipes. The
GD
dataset models co-authorship in the Graph Drawing conference.
The vertices represent 506 authors and an edge between two vertices indicates that this
pair of authors have co-authored a paper. For each dataset, we randomly sample vertices
and edges creatinggraphs with different sizes and densities. The number of vertices is
40 (
small
)and120 (
large
), and the edge density is 1
.
5 (
sparse
)and2
.
5 (
dense
), mak-
ing a total of 4 unweighted undirected graphs per dataset. Section 3.1 explains why we
choose these sizes and densities.
We use two classical straight-line drawing algorithms implemented in G
RAPH
V
IZ
[6].
The
Recipes
graphs are embedded using the multidimensional scaling layoutalgorithm;
for this purpose, we utilize the
neato
tool in G
RAPH
V
IZ
. For drawing the
GD
graphs,
we use the force-directed placement algorithm,
fdp
in G
RAPH
V
IZ
. In order to perform
our experiments, we need to have layouts of the same graph with different number of
crossings. To this end, we run the layoutalgorithms 10
,
000 times on the same graph,
varying the initial positions of the vertices. Since both algorithms are sensitive to the