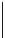Java Reference
In-Depth Information
36 17
28
23
20
36
14
28
13
17
20
36
20 13
14
15
13
17
15
23
14
15
23
28
Runs of length 1
Runs of length 2
Runs of length 4
Figure8.6
A simple external Mergesort algorithm. Input records are divided
equally between two input files. The first runs from each input file are merged and
placed into the first output file. The second runs from each input file are merged
and placed in the second output file. Merging alternates between the two output
files until the input files are empty. The roles of input and output files are then
reversed, allowing the runlength to be doubled with each pass.
A more general problem with adapting an internal sorting algorithm to exter-
nal sorting is that it is not likely to be as efficient as designing a new algorithm
with the specific goal of minimizing disk I/O. Consider the simple adaptation of
Quicksort to use a buffer pool. Quicksort begins by processing the entire array of
records, with the first partition step moving indices inward from the two ends. This
can be implemented efficiently using a buffer pool. However, the next step is to
process each of the subarrays, followed by processing of sub-subarrays, and so on.
As the subarrays get smaller, processing quickly approaches random access to the
disk drive. Even with maximum use of the buffer pool, Quicksort still must read
and write each record log n times on average. We can do much better. Finally,
even if the virtual memory manager can give good performance using a standard
Quicksort, this will come at the cost of using a lot of the system's working mem-
ory, which will mean that the system cannot use this space for other work. Better
methods can save time while also using less memory.
Our approach to external sorting is derived from the Mergesort algorithm. The
simplest form of external Mergesort performs a series of sequential passes over
the records, merging larger and larger sublists on each pass. The first pass merges
sublists of size 1 into sublists of size 2; the second pass merges the sublists of size
2 into sublists of size 4; and so on. A sorted sublist is called a run. Thus, each pass
is merging pairs of runs to form longer runs. Each pass copies the contents of the
file to another file. Here is a sketch of the algorithm, as illustrated by Figure 8.6.
1. Split the original file into two equal-sized run files.
2. Read one block from each run file into input buffers.
3. Take the first record from each input buffer, and write a run of length two to
an output buffer in sorted order.
4. Take the next record from each input buffer, and write a run of length two to
a second output buffer in sorted order.
5. Repeat until finished, alternating output between the two output run buffers.
Whenever the end of an input block is reached, read the next block from the