Java Reference
In-Depth Information
(A)
(B)
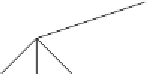
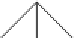
Figure6.16
Full and complete 3-ary trees. (a) This tree is full (but not complete).
(b) This tree is complete (but not full).
6.5
Sequential Tree Implementations
Next we consider a fundamentally different approach to implementing trees. The
goal is to store a series of node values with the minimum information needed to
reconstruct the tree structure. This approach, known as a sequential tree imple-
mentation, has the advantage of saving space because no pointers are stored. It has
the disadvantage that accessing any node in the tree requires sequentially process-
ing all nodes that appear before it in the node list. In other words, node access must
start at the beginning of the node list, processing nodes sequentially in whatever
order they are stored until the desired node is reached. Thus, one primary virtue
of the other implementations discussed in this section is lost: efficient access (typi-
cally (log n) time) to arbitrary nodes in the tree. Sequential tree implementations
are ideal for archiving trees on disk for later use because they save space, and the
tree structure can be reconstructed as needed for later processing.
Sequential tree implementations can be used to serialize a tree structure. Seri-
alization is the process of storing an object as a series of bytes, typically so that the
data structure can be transmitted between computers. This capability is important
when using data structures in a distributed processing environment.
A sequential tree implementation typically stores the node values as they would
be enumerated by a preorder traversal, along with sufficient information to describe
the tree's shape. If the tree has restricted form, for example if it is a full binary tree,
then less information about structure typically needs to be stored. A general tree,
because it has the most flexible shape, tends to require the most additional shape
information. There are many possible sequential tree implementation schemes. We
will begin by describing methods appropriate to binary trees, then generalize to an
implementation appropriate to a general tree structure.
Because every node of a binary tree is either a leaf or has two (possibly empty)
children, we can take advantage of this fact to implicitly represent the tree's struc-
ture. The most straightforward sequential tree implementation lists every node
value as it would be enumerated by a preorder traversal. Unfortunately, the node
values alone do not provide enough information to recover the shape of the tree. In
particular, as we read the series of node values, we do not know when a leaf node
has been reached. However, we can treat all non-empty nodes as internal nodes