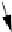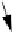Java Reference
In-Depth Information
HEAD
CURR
TAIL
20
23
12
15
(A)
HEAD
CURR
TAIL
20
23
10
12
15
(B)
Figure4.6
Insertion using a header node, with
curr
pointing one node head of
the current element. (a) Linked list before insertion. The current node contains 12.
(b) Linked list after inserting the node containing 10.
CURR
TAIL
HEAD
Figure4.7
Initial state of a linked list when using a header node.
node like any other, but its value is ignored and it is not considered to be an actual
element of the list. The header node saves coding effort because we no longer need
to consider special cases for empty lists or when the current position is at one end
of the list. The cost of this simplification is the space for the header node. However,
there are space savings due to smaller code size, because statements to handle the
special cases are omitted. In practice, this reduction in code size typically saves
more space than that required for the header node, depending on the number of
lists created. Figure 4.7 shows the state of an initialized or empty list when using a
header node.
Figure 4.8 shows the definition for the linked list class, named
LList
. Class
LList
inherits from the abstract list class and thus must implement all of Class
List
's member functions.
Implementations for most member functions of the
list
class are straightfor-
ward. However,
insert
and
remove
should be studied carefully.
Inserting a new element is a three-step process. First, the new list node is
created and the new element is stored into it. Second, the
next
field of the new
list node is assigned to point to the current node (the one after the node that
curr
points to). Third, the
next
field of node pointed to by
curr
is assigned to point to
the newly inserted node. The following line in the
insert
method of Figure 4.8
does all three of these steps.
curr.setNext(newLink<E>(it,curr.next()));