Information Technology Reference
In-Depth Information
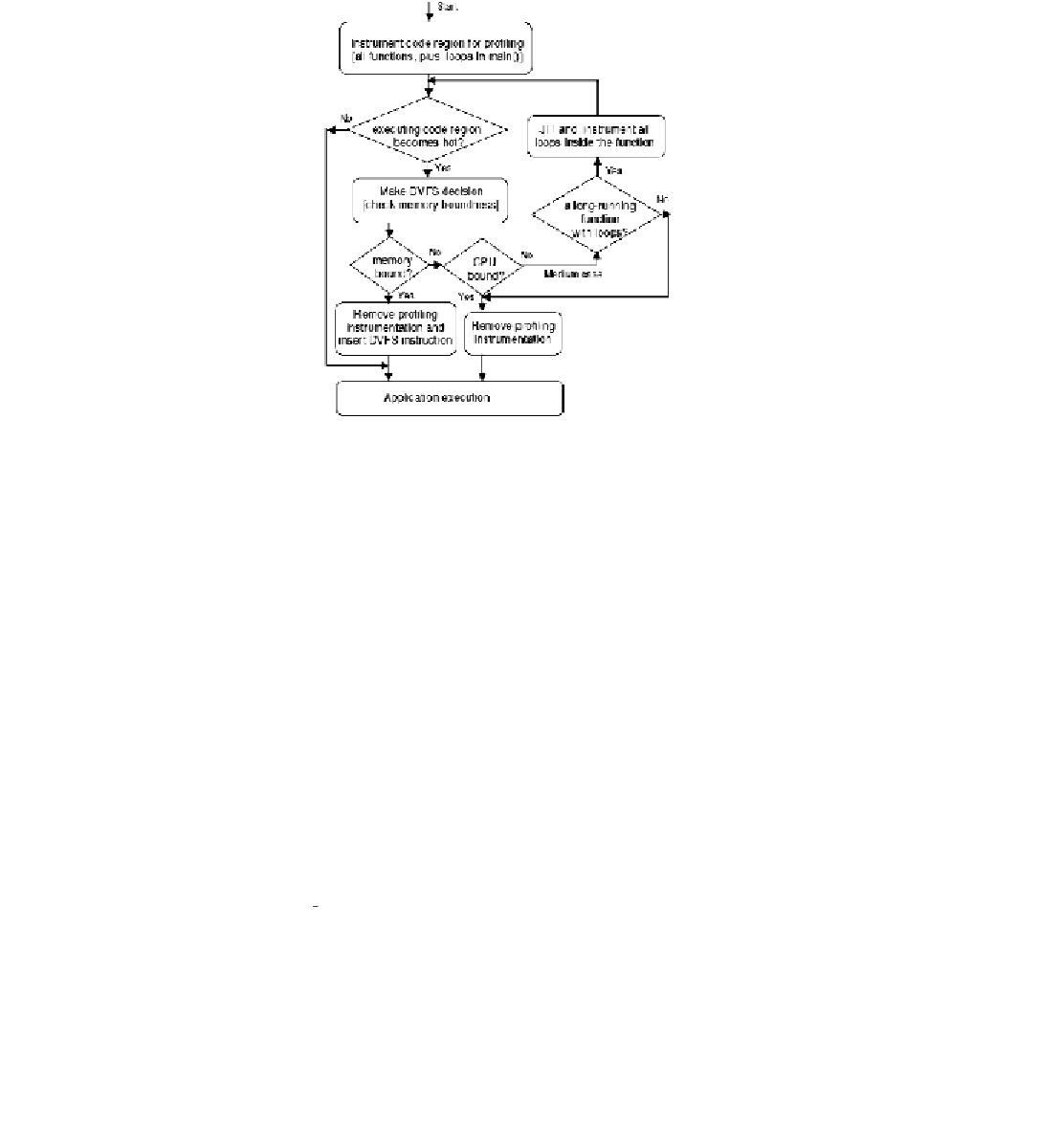
FIGURE 3.3:
RDO flowchart. Reproduced from [
226
]. Copyright 2005 IEEE.
slowing it down does not hurt the overall performance and can save power. DVFS approaches,
after all, are exploiting slack. If the code is CPU-bound, it is left alone since slowing it down
could seriously degrade the performance. If a decision for memory- or CPU-boundedness
cannot be made and the region is large enough, it is divided up into smaller regions and the
algorithm repeats for each of the smaller regions.
The analytic model determines slack in the CPU due to memory operations. The model
divides CPU execution into execution that happens
concurrently
with outstanding memory
operations and execution that
depends
on memory operations (Figure 3.4). The concurrent
execution, hidden behind the latency (
t
asym mem
) of a memory operation can be
stretched
to
take up slack. The more a code region is characterized by this type of execution the slower it
can run without affecting the end performance too much. At run-time, the analytic model is
approximated using hardware performance counters. These counters provide information on
the number of retired micro-operations (µops) per memory bus transaction (which relates to
the memory latency
t
asym mem
), and the number of completed instructions during outstanding
memory (operations which relates to the portion of concurrent execution) [
226
].
Power measurements were taken on an actual system using RDO on a variety of bench-
marks. The experimental setup consisted of a voltage/current measurement unit (measuring the
voltage and current drawn by the target processor), a signal conditioning unit (to reduce noise
in measurements), a data acquisition unit, and a second computer acting as a data logging and
Search WWH ::

Custom Search