Database Reference
In-Depth Information
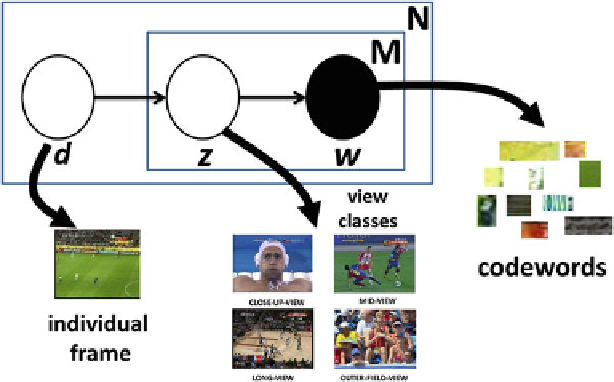
Fig. 9.3
Illustration of the PLSA model in plate notation and its connection with view type
classification
Since SVMs have demonstrated great performance in the field of classification,
it is adopted in our view classification task for comparison purposes. In general,
supervised models tend to yield better results but require predefined knowledge.
A typical radial basis function (RBF) is used as the non-linear kernel in SVM [
289
]
and shown in Eq. (
9.3
). In this equation,
x
i
and
x
j
represent the codewords, and
ʳ
is
the kernel parameter of the RBF.
2
K
(
x
i
,
x
j
)=
exp
(
−
ʳ
x
i
−
x
j
)
,
ʳ
>
0
.
(9.3)
Four view types are defined, namely close-up-view, mid-view, long-view and
outer-field-view. This definition is also popular among other work in this field [
243
,
244
,
273
]. For the PLSA-based model, the number of view types is required, while
labeling effort is not needed for individual frames. On the contrary, SVM-based
models demand both semantic predefined view types as well as all frames labeled
with groundtruth, which could be unaffordable when the video is large in size.
As a result of the view classification task, the query video sequence is labeled
with view types. In the next section, models which take labeled video sequence as
input for detecting interesting events are introduced.
Search WWH ::

Custom Search