Database Reference
In-Depth Information
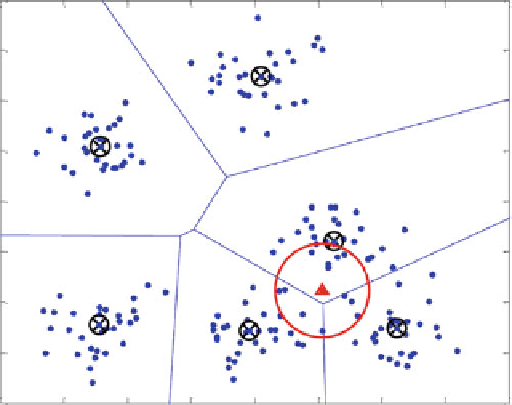
Fig. 8.4
Example illustrating cluster selection for a query
precision of searching 20 query images selected from Boeing airplanes and Bonsai
classes. The result shows that the precision increased with the number of clusters,
k
. However, after
k
=
8, there was no improvement at all. It is also observed that,
beyond
k
8, all the additional similarity matching efforts (i.e., up to approximately
90 % of all images) are wasted. Figure
8.6
shows the number of total images (i.e.,
search space) belonging to these clusters. It is observed that the number of images
continuously increased as
k
increased.
≥
8.3.3.2
Routing of Query
In order to facilitate routing queries, the Chord offers an identifier space of size
2
m
. This space is used to distribute data items and nodes in a circle in a clockwise
direction, as illustrated in Fig.
8.3
for
m
5. The identifier of a data item is referred
to as k (for
key
) and the identifier of a peer is referred to as N (for
node
). The closest
peer with
N
=
>
in which k is the key (hash of
clusID
of an image), and URL is the data containing
information about the peer server that has the image.
To find an image that has the same cluster as a query (a relevant image), a peer
needs to know the node that is responsible for that image: the peer that stores the
index entry (a reference to that image). As discussed previously, a peer that is the
successor of a key in the ring is the responsible peer for the key. Let us define
the function successor(k) as the node identifier of the first actual node following
k around the circle clockwise. Finding the responsible node is actually finding the
successor of a key. For example, in Fig.
8.3
, successor(k14) = N17.
≥
k
is called the successor of k, and hosts the index entry
<
k
,
f
v
,
URL
Search WWH ::

Custom Search