Database Reference
In-Depth Information
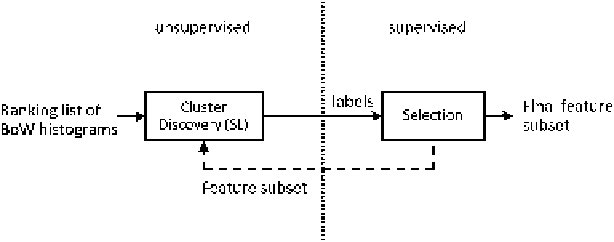
Fig. 5.2
The procedure for the unsupervised wrapper approach, where a ranking list of BoW
vectors is fed into a clustering algorithm whose results are used to perform feature selection.
The unsupervised cluster discovery procedure is performed by the single-linkage (SL) method,
generating “class labels” for each cluster. These cluster labels are used by the feature selection
method
denote the BoW vector corresponding to the
r
-the training image in
Eq. (
5.20
), with
h
j
denoting the
j
-th element of any vector
h
. For the ranking result
in Eq. (
5.20
), there are a total of
R
training samples, each of which is denoted by an
M
-dimensional vectors:
Let
h
(
r
)
⊡
⊣
⊤
⊦
,
h
1
(
r
)
h
2
(
r
)
h
(
r
)=
r
=
1
,...,
R
(5.21)
.
h
M
(
r
)
Then, a data matrix can be explicitly expressed as follows:
H
=[
h
(
1
)
,
h
(
2
)
,···,
h
(
R
)]
(5.22)
⊡
⊤
(
)
(
)
...
(
)
h
1
1
h
1
2
h
1
R
⊣
⊦
(
)
(
)
...
(
)
h
2
1
h
2
2
h
2
R
=
(5.23)
.
.
.
.
.
.
h
M
(
1
)
h
M
(
2
)
...
h
M
(
R
)
Let
the
dimension-reduced
representation
of
h
(
t
)
be
denoted
as
an
m
-
dimensional vector:
t
y
(
r
)=[
y
1
(
r
)
,
y
2
(
r
)
, ...,
y
m
(
r
)]
,
r
=
1
,...,
R
(5.24)
where
m
M
. The feature selection algorithm chooses
m
most useful features from
the original
M
features. Each of the new representations
y
i
(
≤
r
)
,
i
=
1
,...,
m
will be
simply one of the original features.
Search WWH ::

Custom Search